Swin Transformer的提出让Transformer代替CNN作为计算机视觉领域多类下游任务的特征提取骨干网络,下文主要记录Swin Transformer的基本结构。 这里是官方代码链接[1]和论文链接[2]。
Swin Transformer的提出动机
Transformer在NLP领域大展身手,但将Transformer迁移到CV领域,会面临两个困难:
- 尺度问题:在一些CV任务中,比如目标检测问题,具有相同语义的实例由于尺度的问题,在图像中占据不同的像素规模,但目前基于Transformer的方法中,图像切片都是固定大小的。
- 计算复杂度:图像的特征张量展开成向量的方式计算自注意力这个过程,当图像分辨率稍大时,该过程的复杂度将变得难以忍受,因为此时的计算复杂度将与图像大小的平方成正比,这让Transformer在诸如语义分割的下游任务(需要像素级别的标签预测)中遇到困难。
为了解决上述问题,作者提出的Swin Transformer仅在局部窗口计算自注意力,并提出用Shifted windows得到特征的全局上下文信息(全局特征)。
网络结构
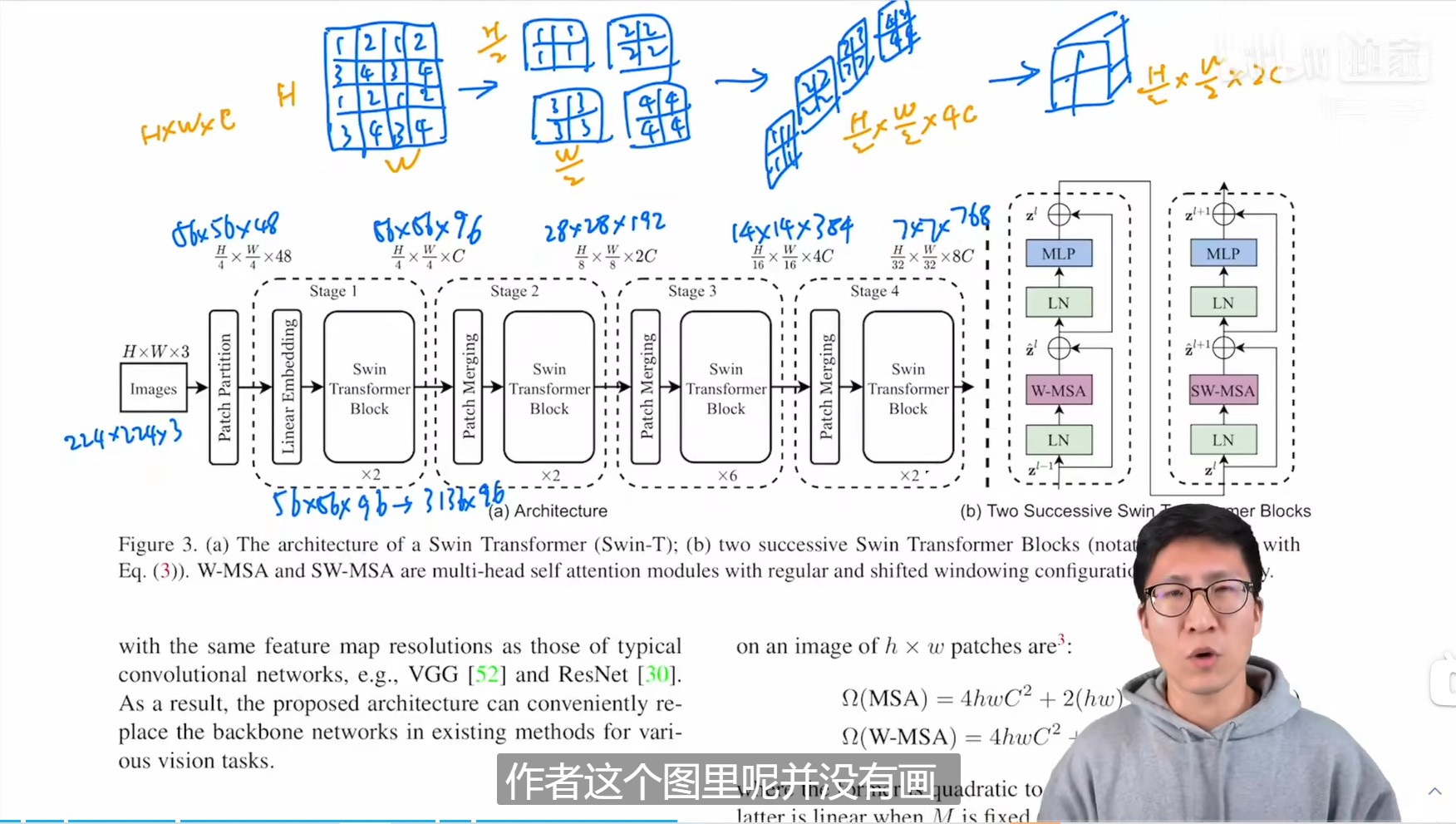
Swin Transformer(Swin-T)网络结构如下图:
 ◎ 图一 Swin Transformer (Swin-T) 的网络结构
◎ 图一 Swin Transformer (Swin-T) 的网络结构
假设网络输入图像尺寸是$H \times W \times 3$,经过Patch Partition模块后被分为互不重叠的patches,注意在论文中patch是最小的计算单元,一个patch区域的特征后续会被展开成一个向量用于计算自注意力。在论文中patch被设置为$4 \times 4$的像素方块,所以经过Patch Partition模块后的特征图维度是$\frac{H}{4} \times \frac{W}{4} \times 48$。网络后续部分被分成四个Stage,除了Stage1是Linear Embedding模块与Swin Transformer Block的组合,后续的Stage都是Patch Merging与Swin Transformer Block的组合。Stage1中的linear embedding层将特征维度变换为$\frac{H}{4} \times \frac{W}{4} \times C$,Swin Transformer Block即论文提出的修改版本的Transformer模块,将在下文具体介绍。Patch Merging对特征图采用步长为2的等间隔采样,并将采样后的特征图在通道维度上合并,此时特征图的分辨率将降采样为原来的$\frac{1}{4}$,通道为从$C$提升为$4C$,并通过一个线性变换层转换为$2C$。
标准的Transformer由于需要计算全局自注意力,它的计算复杂度随着图像大小增长呈平方关系。为了解决计算复杂度的问题,论文提出让Swin Transformer Block只在一个区域(windows,论文将windows固定为7$\times$7个patch,patch是最小的计算单元)中计算自注意力。全局的MSA和基于窗口的MSA的计算复杂度如下所示(仅考虑乘法操作):
 ◎ 图二 MSA与W-MSA计算复杂度
然而这样的方式中只能得到局部注意力,论文的主要贡献点在于提出了Shifted windows 的操作,Swin Transformer Block总是两两组合的,每次运算都会包括在原始windows中计算自注意力,以及在Shifted windows中计算自注意力,所以看上图中的虚线框每个stage的Swin Transformer Block的数目都是偶数,这样得到的特征已经能得到较大的感受野,多次运行Swin Transformer Block后,最终的特征能得到全局的感受野。
◎ 图二 MSA与W-MSA计算复杂度
然而这样的方式中只能得到局部注意力,论文的主要贡献点在于提出了Shifted windows 的操作,Swin Transformer Block总是两两组合的,每次运算都会包括在原始windows中计算自注意力,以及在Shifted windows中计算自注意力,所以看上图中的虚线框每个stage的Swin Transformer Block的数目都是偶数,这样得到的特征已经能得到较大的感受野,多次运行Swin Transformer Block后,最终的特征能得到全局的感受野。
两个Swin Transformer Block的组合方式如图一中(b) Two Successive Swin Transformer Blocks所示,W-MSA代表当前windows的多头自注意力网络,SW-MSA代表Shifted windows的多头自注意力网络。
至于为了解决尺度的问题,Swin Transformer引入Patch Merging操作,模拟CNN中的池化操作,经过Patch Merging后特征图的分辨率下降,但特征通道维数增加了,这与CNN的骨干网络的效果是一样的。Shifted windows和Patch Merging的操作会在下文介绍。
Shifted windows
Shifted windows的示意图如下:
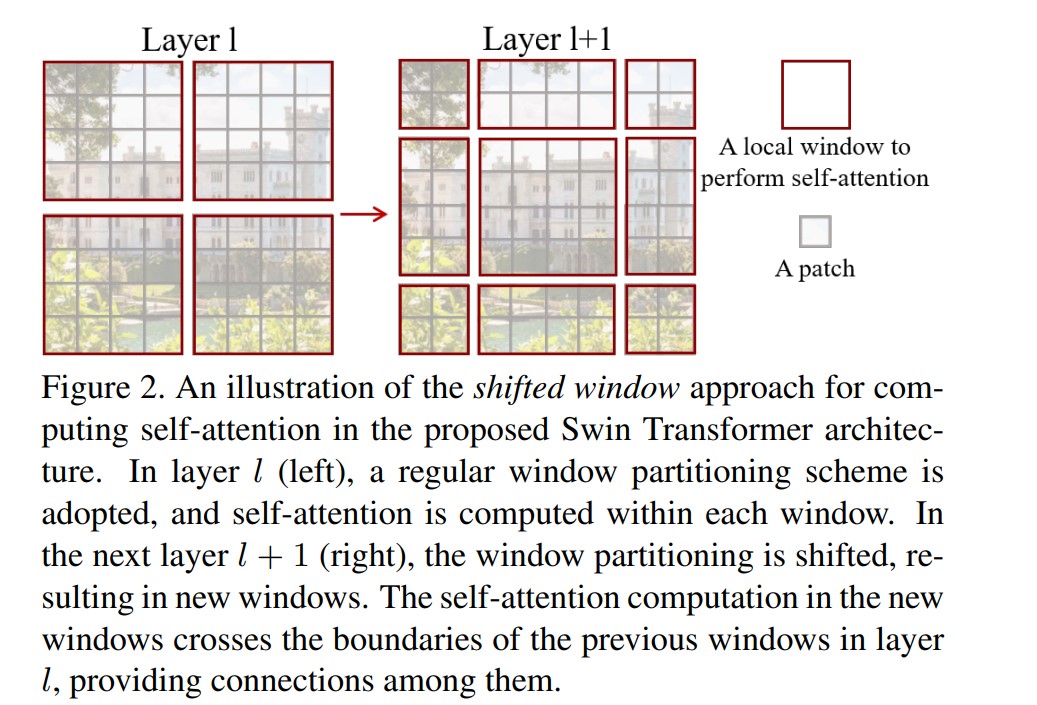 ◎ 图三 Shifted windows
◎ 图三 Shifted windows
在上图中,一个大小为$M \times M$($M$在论文里设定为7,如果特征图大小不能被$M$整除,则先零填充特征图)经过基础版本的Shifted windows操作后,4个windows会被分为9个windows,每个windows将分别计算自注意力,这样存在的问题是:由于每个windows并不是保持一样的大小,这给代码实现时并行化处理带来麻烦,降低了运算效率,论文中Shifted windows的实现巧妙地利用掩码(mask)的MSA层解决该问题,如下图所示:
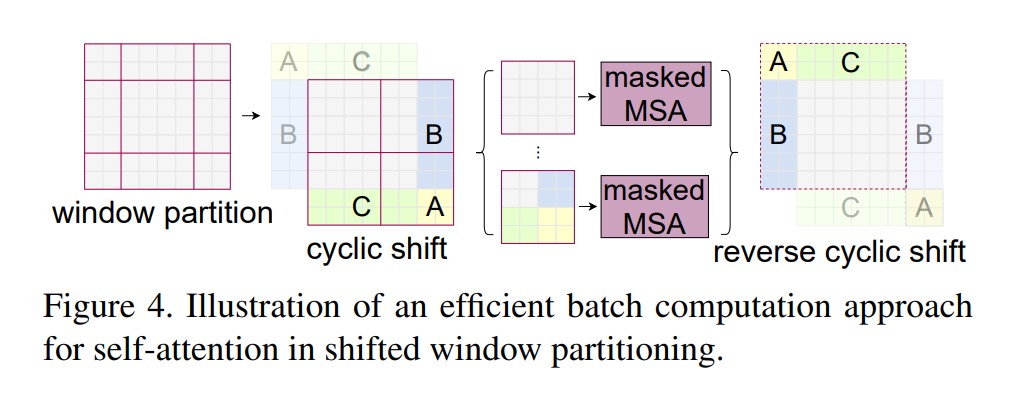 ◎ 图四 Shifted windows的高效实现
◎ 图四 Shifted windows的高效实现
从上图中看出,论文将9个windows重新填补成4个windows并做好标记(标记该张量原本来自哪里),然后对该4个windows计算W-MSA,但这样的操作会为本不应该计算注意力系数的向量之间也计算了注意力系数,因为重新填充后的窗口的向量很可能是不相关的。masked MSA的操作在重新填补的windows计算MSA时,为不应该计算注意力系数的区域填充一个很大的负数,这样MSA经过后续的softmax操作后,该区域将归零。这样,通过masked MSA的处理,虽然总的计算量提高了,但由于windows大小变的一致,硬件并行化实现反而然模型的运算效率提高了。masked MSA的计算示意图如下所示:
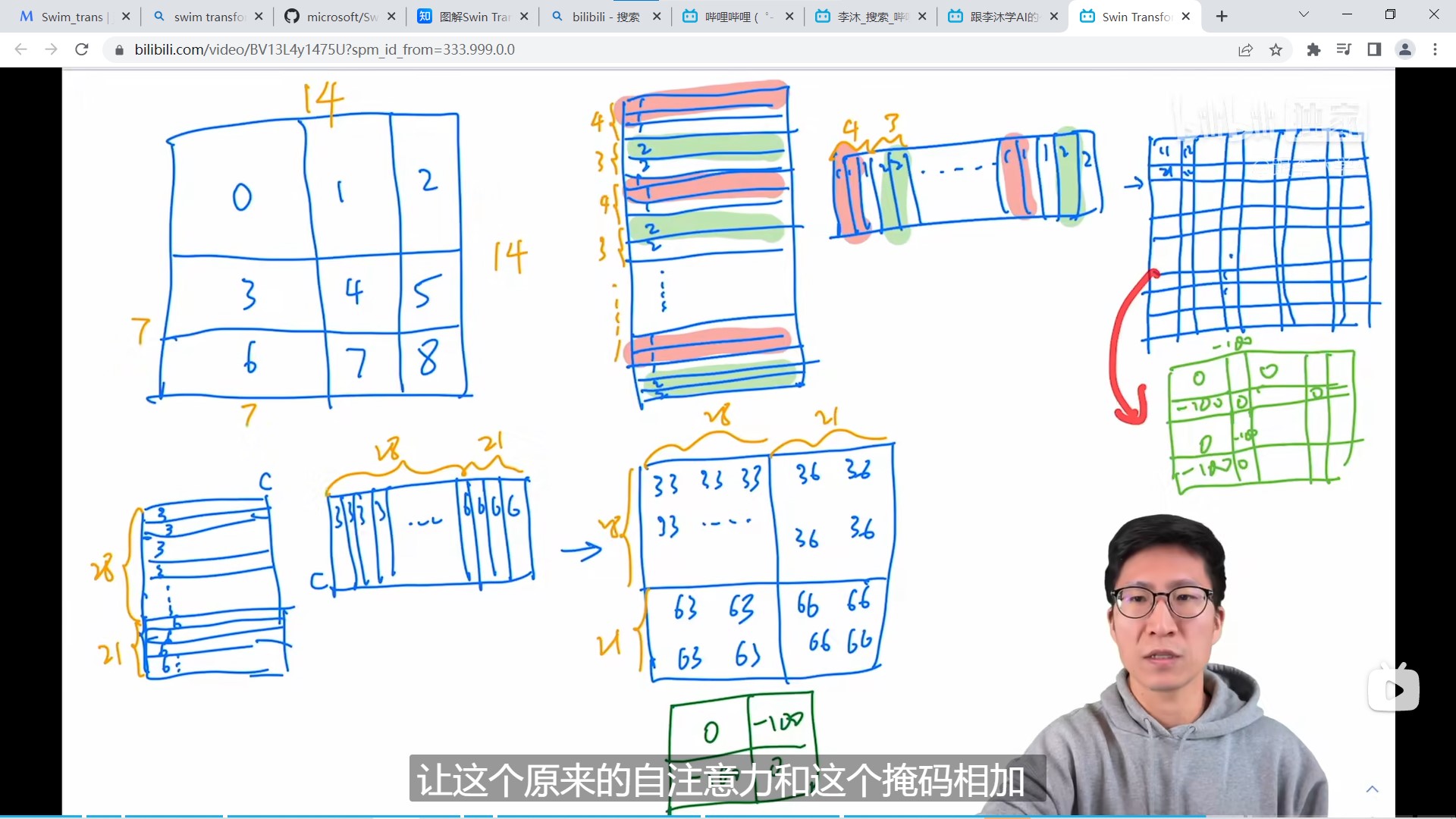 ◎ 图五 masked MSA示意图
◎ 图五 masked MSA示意图
mask的可视化如下所示:
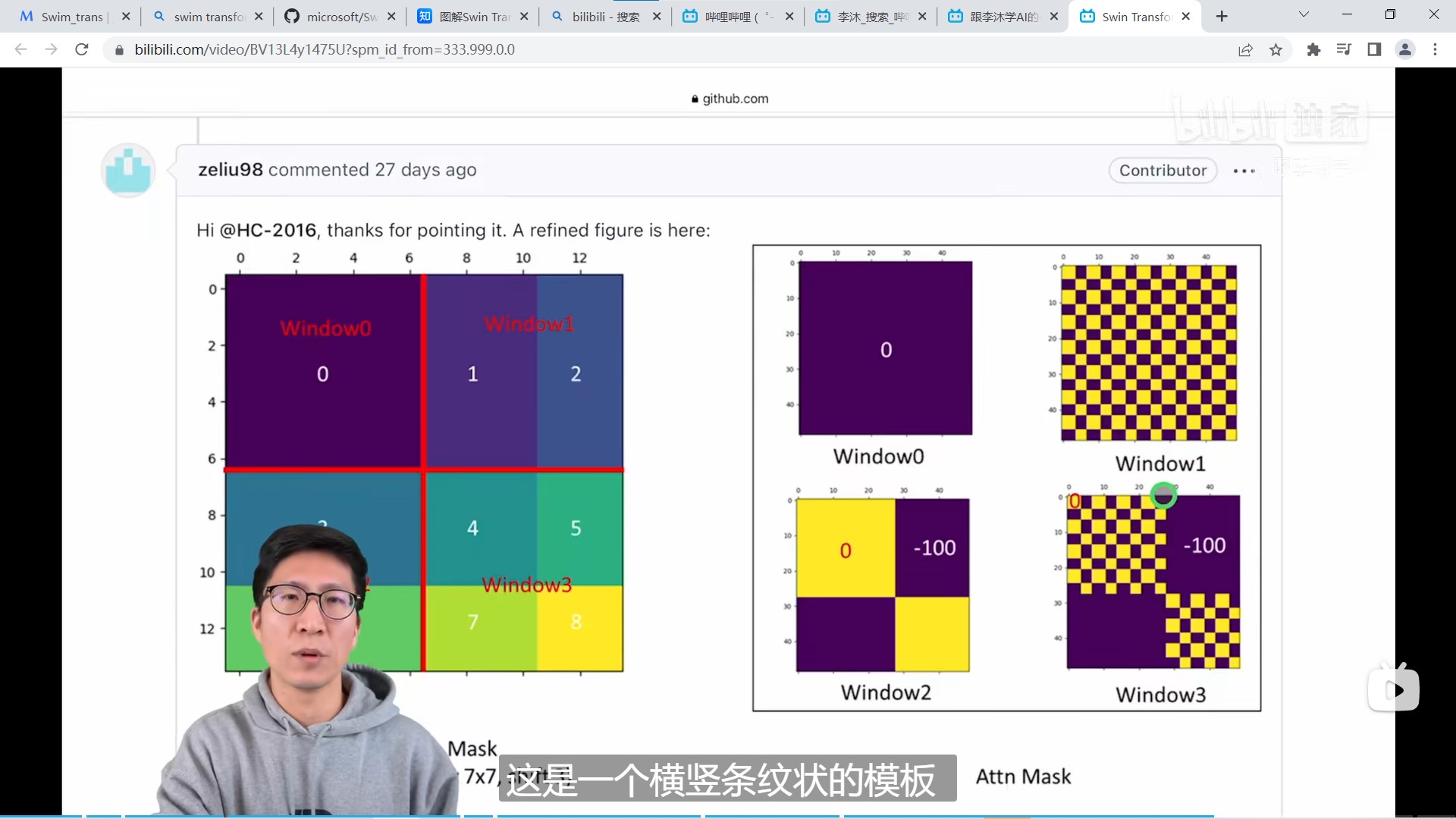 ◎ 图六 mask的可视化
◎ 图六 mask的可视化
Patch Merging
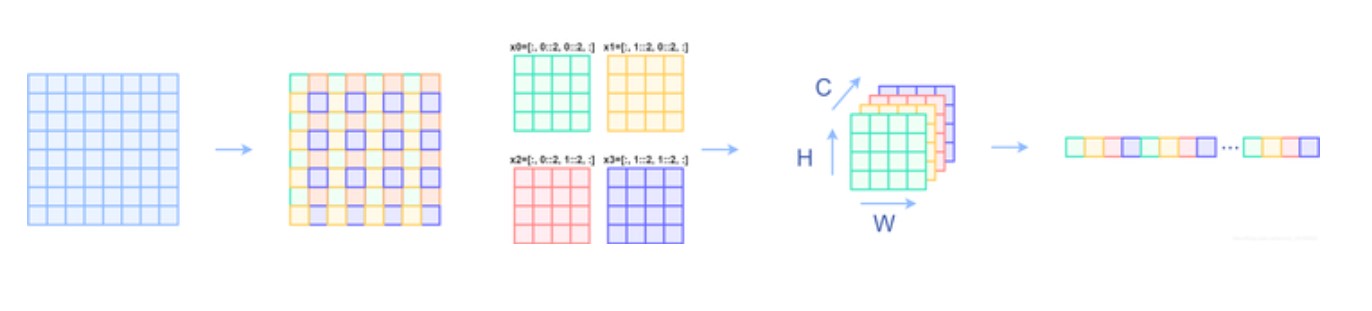
 ◎ 图七 Patch Merging示意图1
◎ 图七 Patch Merging示意图1
如上图,Patch Merging会在每个stage开始时调整特征图分辨率,改变特征图的通道数,由于Swin Transformer Block不改变向量的通道数和特征图分辨率,这两者的改变都由Patch Merging实现。Patch Merging的做法时在行方向和列方向上,间隔2选取元素,然后拼接在一起作为一整个张量,最后展开。此时通道维度会变成原先的4倍(因为H,W各缩小2倍),此时再通过一个全连接层再调整通道维度为原来的两倍。
 ◎ 图八 Patch Merging示意图2
◎ 图八 Patch Merging示意图2
相对位置编码
对于一个大小是$Wh \times Ww$的窗口,每个patch的横坐标到其他patch的横坐标的距离(偏移)的取值范围是$(-(Wh-1), (Wh-1))$,每个patch的纵坐标到其他patch的纵坐标的距离(偏移)的取值范围是$(-(Ww-1), (Ww-1))$,分别把取值调整为$(0, (2 \times Wh-1))$,$(0, (2 \times Ww-1))$,故作者维持一个大小是$(2Wh-1) \times (2Ww-1)$的偏置矩阵$\hat{B}$(relative_position_bias_table),该偏置矩阵是一个可学习参数组成的二维矩阵。对于一个$Wh \times Ww$的窗口,需要得到每个patch到其他patch的相对位置编码,方法是计算一个相对坐标矩阵(relative_coords),该矩阵的维度是$(Wh * Ww)\times(Wh * Ww)$,如下图所示,最终每个位置的相对位置编码根据relative_coords的值当作索引从relative_position_bias_table中取得。关于相对位置编码可以结合下文的代码理解。
 ◎ 图九 相对位置编码
◎ 图九 相对位置编码
代码结构
首先从model = build_model(config)进入模型构建的代码:
|
|
这里我们关注SwinTransformer的构建,swin_mlp将SwinTransformer中的Swin Transformer Block改为了mlp实现。
我们看SwinTransformer的forward函数:
|
|
其中在forward_features函数中,特征x首先经过patch_embed,然后依次经过SwinTransformer的layer:
|
|
最后是送进分类头之前将特征reshape成$B \times C$的维度:
|
|
在这里再次贴上Swim Transformer的网络结构图(Swim-T):
◎ 图十 Swin Transformer (Swin-T) 的网络结构
代码中patch_embed其实做了结构图中的Patch Partition和Linear Embedding的工作:
|
|
再看self.layers:
|
|
代码中downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,除了最后一层,前面每一层都添加downsample,也即上图中的Patch Merging操作。我们再看BasicLayer,它主要由SwinTransformerBlock和downsample组成(除了最后一层)。
|
|
重点看SwinTransformerBlock:
|
|
SwinTransformerBlock类处理带有Shifted windows的自注意力计算和正常windows的自注意力计算。SwinTransformerBlock首先会对特征进行窗口划分partition windows,计算完窗口注意力后再做窗口合并merge windows:
|
|
这里的重点代码在于中间的窗口注意力WindowAttention的计算过程:
|
|
WindowAttention部分代码如下:
|
|
关于相对位置编码,代码中维护一个relative_position_bias_table和relative_coords,每个windows的相对位置编码relative_position_bias从中取值:
|
|
对于SW-MSA,它比W-MSA多了一个cyclic shift和mask操作,cyclic shift的操作之后还有reverse cyclic shift操作,防止自注意力的计算会一直往图像右下角偏移:
|
|
mask的生成代码如下:
|
|
attn_mask作为一个常量数据被注册。这样SwinTransformerBlock就走完了,对于一个BasicLayer,在SwinTransformerBlock之后还有downsample层,它负责将特征图降采样并提升通道维数:
|
|
self.reduction将通道维数从$4C$降到$2C$,这样特征图通过downsample层后,通道维数只提高两倍。
特征图经过多层BasicLayer后,最终被送进分类头,完成整个正向过程。
更多关于Swin Transformer
可以看b站李沐的Swin Transformer论文精读[3],代码讲解看知乎文章图解Swin Transformer[4]。