HRNet 是一个很实用的骨干网络,在对目标位置敏感,需要输出高分辨率特征图的计算机视觉任务中表现很好,比如目标检测,语义分割,人体姿态估计, facial landmark estimate 等任务。
不同于以往先用从高分辨率到低分辨率网络编码低分辨率特征图结构(ResNet,VGGNet),再解码为高分辨率特征图的网络.文章从高分辨率子网络(high-resolution subnetwork)作为第一阶段开始,逐步增加高分辨率到低分辨率的子网,形成更多的阶段,并将多分辨率子网并行连接。通过进行多次多尺度融合 multi-scale fusions ,使得每一个高分辨率到低分辨率的表征都从其他并行表示中反复接收信息,从而得到丰富的高分辨率表征。

HRNet 的各类应用见 github官网。
【论文阅读笔记】HRNet--从代码来看论文这篇文章讲的很详细,不重复造轮子了,在这里我补充上我看代码时觉得注意的一些点。
models.py里面的参数定义:
1
2
3
|
POSE_HIGH_RESOLUTION_NET.STAGE2.NUM_MODULES = 1
POSE_HIGH_RESOLUTION_NET.STAGE2.NUM_BRANCHES = 2
POSE_HIGH_RESOLUTION_NET.STAGE2.NUM_BLOCKS = [4, 4]
|
这里分清楚 STAGE,MODULES,BRANCHES,BLOCKS分别代表什么含义,上图的网络结构图中整个代表一个MODULES,该MODULES横向分为四个STAGE:
STAGE1没有分支BRANCHES;
STAGE2有两个分支BRANCHES,每个BRANCHES有四个BLOCKS;
STAGE3有三个分支BRANCHES,每个BRANCHES有四个BLOCKS;
STAGE4有四个分支BRANCHES,每个BRANCHES有四个BLOCKS;
代码中还有两个重要的概念:
在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
class HighResolutionModule(nn.Module):
...
...
...
def _make_fuse_layers(self):
if self.num_branches == 1:
return None
num_branches = self.num_branches
num_inchannels = self.num_inchannels
fuse_layers = []
for i in range(num_branches if self.multi_scale_output else 1):
fuse_layer = []
for j in range(num_branches):
# 1x1卷积,再上采样
if j > i:
fuse_layer.append(nn.Sequential(
nn.Conv2d(num_inchannels[j],
num_inchannels[i],
1,
1,
0,
bias=False),
nn.BatchNorm2d(num_inchannels[i],
momentum=BN_MOMENTUM),
nn.Upsample(scale_factor=2**(j-i), mode='nearest')))
elif j == i:
fuse_layer.append(None)
else:
#降采样,采样数和隔的层数相关,比如相邻层采样率为2**1,隔一层采样率为2**2,最后一层输出不用relu
conv3x3s = []
for k in range(i-j):
if k == i - j - 1:
num_outchannels_conv3x3 = num_inchannels[i]
conv3x3s.append(nn.Sequential(
nn.Conv2d(num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False),
nn.BatchNorm2d(num_outchannels_conv3x3,
momentum=BN_MOMENTUM)))
else:
num_outchannels_conv3x3 = num_inchannels[j]
conv3x3s.append(nn.Sequential(
nn.Conv2d(num_inchannels[j],
num_outchannels_conv3x3,
3, 2, 1, bias=False),
nn.BatchNorm2d(num_outchannels_conv3x3,
momentum=BN_MOMENTUM),
nn.ReLU(False)))
fuse_layer.append(nn.Sequential(*conv3x3s))
fuse_layers.append(nn.ModuleList(fuse_layer))
return nn.ModuleList(fuse_layers)
|
中的
1
|
for i in range(num_branches if self.multi_scale_output else 1):
|
当self.multi_scale_output == True时会执行特征融合,而在代码里设置每个STAGE都会执行该操作,上面代码的特征融合规则是,对于待融合分支BRANCHES的特征图,当与之融合的特征图分辨率更大,需要通过卷积降低分辨率,相同BRANCHES的特征图不执行操作(则后续直接相加),当与之融合的特征图分辨率更小,需要先进行1X1卷积让两特征图的通道数一致,再通过上采样操作加大分辨率,特征融合规则是直接相加。
注意代码:
1
2
3
|
for i in range(num_branches if self.multi_scale_output else 1):
fuse_layer = []
for j in range(num_branches):
|
进行融合的BRANCHES数是一致的,新多出来的BRANCHE的特征融合方式,不同于论文的模型图,代码里是直接从最近BRANCHE的融合特征图通过卷积降采样得到。
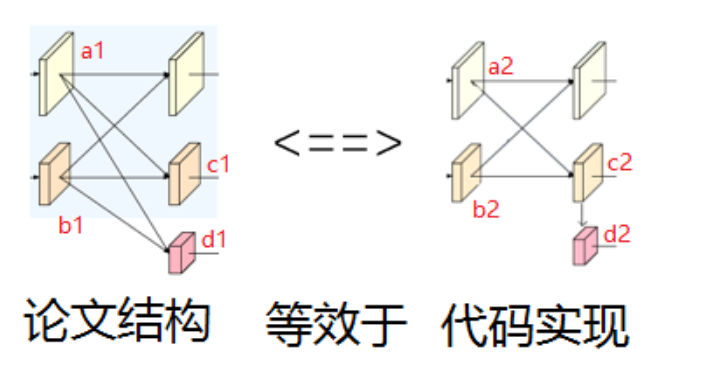
详细代码见:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
def _make_transition_layer(
self, num_channels_pre_layer, num_channels_cur_layer):
num_branches_cur = len(num_channels_cur_layer)
num_branches_pre = len(num_channels_pre_layer)
transition_layers = []
for i in range(num_branches_cur):
#卷积实现升采样
if i < num_branches_pre:
if num_channels_cur_layer[i] != num_channels_pre_layer[i]:
transition_layers.append(nn.Sequential(
nn.Conv2d(num_channels_pre_layer[i],
num_channels_cur_layer[i],
3,
1,
1,
bias=False),
nn.BatchNorm2d(
num_channels_cur_layer[i], momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)))
else:
transition_layers.append(None)
else:
#卷积实现降采样、或者通道不变
conv3x3s = []
for j in range(i+1-num_branches_pre):
inchannels = num_channels_pre_layer[-1]
outchannels = num_channels_cur_layer[i] \
if j == i-num_branches_pre else inchannels
conv3x3s.append(nn.Sequential(
nn.Conv2d(
inchannels, outchannels, 3, 2, 1, bias=False),
nn.BatchNorm2d(outchannels, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)))
transition_layers.append(nn.Sequential(*conv3x3s))
return nn.ModuleList(transition_layers)
|