要经常参考:TensorRT开发者文档
下载TensorRT:
从 这个链接下载tar包后解压,添加环境变量:
1
2
3
4
|
vim ~/.bashrc
# 添加以下内容
export LD_LIBRARY_PATH=/path/to/TensorRT-7.2.3.4/lib:$LD_LIBRARY_PATH
export LIBRARY_PATH=/path/to/TensorRT-7.2.3.4/lib::$LIBRARY_PATH
|
具体参考内卷成啥了还不知道TensorRT?超详细入门指北,来看看吧!
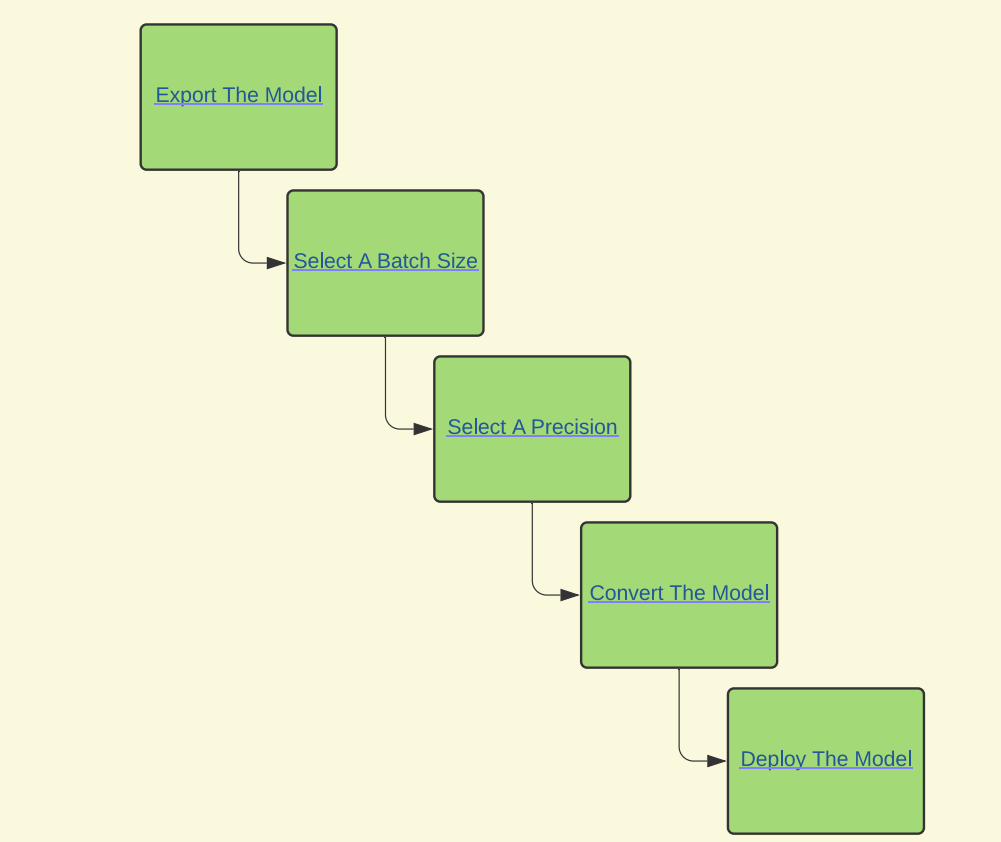
TensorRT的工作流程分为五个步骤:
导出模型-->选择推断的batch size-->选择精度-->转换模型-->部署模型
 ◎ 步骤
◎ 步骤
要将pytorch模型转为trt模型有两个方法:
- automatic ONNX conversion from .onnx files
当遇到trt不支持的op时,需要手写插件。
pytorch模型转换为onnx模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import torch
import torchvision
torch_model_path = "./checkpoints/res50.pth"
export_onnx_path = "./checkpoints/model.onnx"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch_model = torch.load(torch_model_path)
model = torchvision.models.resnet50()
model.load_state_dict(torch_model)
#set the model to inference mode
model.eval().to(device)
batch_size = 1 #批处理大小
input_shape = (3, 64, 64) #输入数据,改成自己的输入shape
x = torch.randn(batch_size, *input_shape).to(device) # 生成张量
y = model(x)
print("y shape: ",y.shape)
torch.onnx.export(model, # 定义的模型
x, # 输入数据
export_onnx_path, # 导出路径
opset_version=13, #opset_version和onnx版本有对应关系
do_constant_folding=True, # 是否执行常量折叠优化
input_names=["input"], # 输入名
output_names=["output"], # 输出名
verbose = True, # 开启 verbose方便调试
)
|
可以利用netron来可视化导出的onnx模型。
pip install netron
netron
注意输入输出的名称。
然后利用onnxruntime验证导出模型是不是正确的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import onnx
import numpy as np
import onnxruntime as rt
model_path = "./checkpoints/model.onnx"
# 验证模型合法性
onnx_model = onnx.load(model_path)
onnx.checker.check_model(onnx_model)
# 设置模型session以及输入信息
sess = rt.InferenceSession(model_path, None)
input_name = sess.get_inputs()[0].name
output_name = sess.get_outputs()[0].name
print('Input Name:', input_name)
print('Output Name:', output_name)
# 输入数据并调整为输入维度
x = np.random.rand(1, 3, 64, 64).astype(np.float32)
output = sess.run(None, {input_name: x})
print(output)
|
onnx模型转为trt模型:
1
|
trtexec --onnx=path_to/model.onnx --saveEngine=path_to/resnet_engine.trt --explicitBatch
|
上面的命令将onnx转为trt模型并且序列化到文件中了。后续可以调用python或者c++api来反序列化.trt文件转为runtime模型,速度会比先解析onnx模型为trt模型再运行要快。
如果要支持动态尺度,这样写:
1
|
./trtexec --explicitBatch --onnx=demo.onnx --minShapes=input:1x1x256x256 --optShapes=input:1x1x2048x2048 --maxShapes=input:1x1x2560x2560 --shapes=input:1x1x2048x2048 --saveEngine=demo.trt --workspace=6000
|
动态尺度支持NCHW中的N、H以及W,也就是batch、高以及宽。
对于动态模型,我们在转换模型的时候需要额外指定三个维度信息即可(最小、最优、最大)。
TensorRT 对网络模型做了算子融合、动态显存分配、精度校准、多steam流、自动调优等操作,在很多模型上推理速度大大提升。
- manually constructing a network using the TensorRT API (either in C++ or Python)
第二种方法更灵活(当然也更难), 这个方法我还在探索中。
 ◎ 工作流程
◎ 工作流程
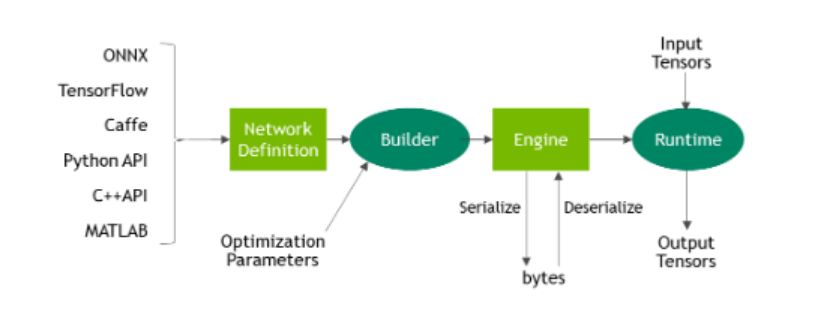
不管是借助onnx通过parser转为到trt模型,还是手工通过API搭建网络加载参数,整个运行流程可以分为下面几个步骤:
- 创建builder(build)
1
|
IBuilder* builder = createInferBuilder(gLogger);
|
gLogger通过下面的方式来创建:
1
2
3
4
5
6
7
8
9
|
class Logger : public ILogger
{
void log(Severity severity, const char* msg) override
{
// suppress info-level messages
if (severity != Severity::kINFO)
std::cout << msg << std::endl;
}
} gLogger;
|
- 创建 engine
1
2
3
4
|
IBuilderConfig* config = builder->createBuilderConfig();
//这里的空间大小需要根据具体需求设置
config->setMaxWorkspaceSize(1 << 20);
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
|
其中的network可以通过parser或者手动装载的方式实现, 比如通过onnx:
1
2
3
4
5
6
7
8
9
|
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
nvonnxparser::IParser* parser =
nvonnxparser::createParser(*network, gLogger);
parser->parseFromFile(onnx_filename, ILogger::Severity::kWARNING);
for (int i = 0; i < parser.getNbErrors(); ++i)
{
std::cout << parser->getError(i)->desc() << std::endl;
}
|
或者手动装载:
1
2
3
4
5
6
7
8
9
|
INetworkDefinition* m_network = builder->createNetworkV2(1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
// tensor
nvinfer1::ITensor *input = m_network->addInput("data",nvinfer1::DataType::kFLOAT, nvinfer1::DimsCHW{static_cast<int>(input_c), static_cast<int>(input_h), static_cast<int>(input_w)});
Layers["input"] = input;
//...很长的网络定义
//...
//...
Layers["relu_eng"] ->setName("output1");
m_network->markOutput(*Layers["relu_eng"]);
|
- 序列化到磁盘下(这一步不是必须的)
1
2
3
4
5
6
7
8
9
10
|
nvinfer1::IHostMemory *serializedModel = engine->serialize();
ofstream engFile;
engFile.open(engPath,ios_base::binary);
engFile.write(static_cast<const char*>(serializedModel->data()),serializedModel->size());
engFile.close();
...
network->destroy();
engine->destroy();
builder->destroy();
serializedModel->destroy();
|
- 反序列化(这一步也不是必须的)
1
2
|
IRuntime* runtime = createInferRuntime(gLogger);
ICudaEngine* engine = runtime->deserializeCudaEngine(modelData, modelSize, nullptr);
|
- 执行推断(infer)
1
2
3
4
5
6
7
|
// 创建 RAII buffer 用于管理数据对象
samplesCommon::BufferManager buffers(mEngine);
//context用于保存网络定义和训练参数等
IExecutionContext *context = engine->createExecutionContext();
//管理输入数据的buffer:输入数据拷贝到buffer中方便管理
...
context->executeV2(buffers.getDeviceBindings().data());
|
首先编写CMakeLists.txt:
cmake_minimum_required(VERSION 2.8)
project(sampleOnnxMNIST)
set(CMAKE_CXX_FLAGS "${CAMKE_CXX_FLAGS} -std=c++11 -pthread")
find_package(CUDA REQUIRED)
include_directories(/usr/local/cuda/include)
link_directories(/usr/local/cuda/lib64)
include_directories(../common)
aux_source_directory(../common SRC_LIST)
# tensorrt
include_directories(/home/jiajie/Learn/TensorRT-7.2.1.61/include/)
link_directories(/home/jiajie/Learn/TensorRT-7.2.1.61/lib/)
find_package(OpenCV)
include_directories(OpenCV_INCLUDE_DIRS)
link_libraries("/home/jiajie/Learn/TensorRT-7.2.1.61/targets/x86_64-linux-gnu/lib/libnvonnxparser.so")
link_libraries("/home/jiajie/Learn/TensorRT-7.2.1.61/targets/x86_64-linux-gnu/lib/libnvcaffe_parser.so")
add_executable(sampleOnnxMNIST ${PROJECT_SOURCE_DIR}/sampleOnnxMNIST.cpp ${SRC_LIST})
target_link_libraries(sampleOnnxMNIST nvinfer)
target_link_libraries(sampleOnnxMNIST cudart)
target_link_libraries(sampleOnnxMNIST ${OpenCV_LIBS})
按照上面TensorRT工作流程, SampleOnnxMNIST只是在这基础上加了很多logging的代码还有代码稳健性的检查,同时没有上面步骤中的序列化到磁盘的步骤。
首先看main()函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
int main(int argc, char** argv)
{
//1. 传参和gLogger,先不用扣细节
samplesCommon::Args args;
bool argsOK = samplesCommon::parseArgs(args, argc, argv);
if (!argsOK)
{
sample::gLogError << "Invalid arguments" << std::endl;
printHelpInfo();
return EXIT_FAILURE;
}
if (args.help)
{
printHelpInfo();
return EXIT_SUCCESS;
}
auto sampleTest = sample::gLogger.defineTest(gSampleName, argc, argv);
sample::gLogger.reportTestStart(sampleTest);
//2. 创建SampleOnnxMNIST对象并初始化参数
SampleOnnxMNIST sample(initializeSampleParams(args));
sample::gLogInfo << "Building and running a GPU inference engine for Onnx MNIST" << std::endl;
//3. 构建trt引擎
if (!sample.build())
{
return sample::gLogger.reportFail(sampleTest);
}
//执行推断
if (!sample.infer())
{
return sample::gLogger.reportFail(sampleTest);
}
return sample::gLogger.reportPass(sampleTest);
}
|
第二步的initializeSampleParams定义了一些外部参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
//!
//! \brief Initializes members of the params struct using the command line args
//!
samplesCommon::OnnxSampleParams initializeSampleParams(const samplesCommon::Args& args)
{
samplesCommon::OnnxSampleParams params;
if (args.dataDirs.empty()) //!< Use default directories if user hasn't provided directory paths
{
params.dataDirs.push_back("data/mnist/");
params.dataDirs.push_back("data/samples/mnist/");
params.dataDirs.push_back("/home/jiajie/baidunetdiskdownload/Find_a_job/Learn_tensorRT/practice/data/mnist/");
}
else //!< Use the data directory provided by the user
{
params.dataDirs = args.dataDirs;
}
params.onnxFileName = "mnist.onnx";
params.inputTensorNames.push_back("Input3");
params.outputTensorNames.push_back("Plus214_Output_0");
params.dlaCore = args.useDLACore;
params.int8 = args.runInInt8;
params.fp16 = args.runInFp16;
return params;
}
|
再看第三步build就很清晰了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
//!
//! \brief Creates the network, configures the builder and creates the network engine
//!
//! \details This function creates the Onnx MNIST network by parsing the Onnx model and builds
//! the engine that will be used to run MNIST (mEngine)
//!
//! \return Returns true if the engine was created successfully and false otherwise
//!
bool SampleOnnxMNIST::build()
{
//创建builder
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
if (!builder)
{
return false;
}
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
//创建network
auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
if (!network)
{
return false;
}
auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config)
{
return false;
}
auto parser
= SampleUniquePtr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger()));
if (!parser)
{
return false;
}
//用parser的方式构造网络
auto constructed = constructNetwork(builder, network, config, parser);
if (!constructed)
{
return false;
}
//buildEngineWithConfig
mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(
builder->buildEngineWithConfig(*network, *config), samplesCommon::InferDeleter());
if (!mEngine)
{
return false;
}
assert(network->getNbInputs() == 1);
mInputDims = network->getInput(0)->getDimensions();
assert(mInputDims.nbDims == 4);
assert(network->getNbOutputs() == 1);
mOutputDims = network->getOutput(0)->getDimensions();
assert(mOutputDims.nbDims == 2);
return true;
}
|
其中的constructNetwork是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
//!
//! \brief Uses a ONNX parser to create the Onnx MNIST Network and marks the
//! output layers
//!
//! \param network Pointer to the network that will be populated with the Onnx MNIST network
//!
//! \param builder Pointer to the engine builder
//!
bool SampleOnnxMNIST::constructNetwork(SampleUniquePtr<nvinfer1::IBuilder>& builder,
SampleUniquePtr<nvinfer1::INetworkDefinition>& network, SampleUniquePtr<nvinfer1::IBuilderConfig>& config,
SampleUniquePtr<nvonnxparser::IParser>& parser)
{
auto parsed = parser->parseFromFile(locateFile(mParams.onnxFileName, mParams.dataDirs).c_str(),
static_cast<int>(sample::gLogger.getReportableSeverity()));
if (!parsed)
{
return false;
}
config->setMaxWorkspaceSize(16_MiB);
if (mParams.fp16)
{
config->setFlag(BuilderFlag::kFP16);
}
if (mParams.int8)
{
config->setFlag(BuilderFlag::kINT8);
samplesCommon::setAllTensorScales(network.get(), 127.0f, 127.0f);
}
samplesCommon::enableDLA(builder.get(), config.get(), mParams.dlaCore);
return true;
}
|
再看第四步infer:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
//!
//! \brief Runs the TensorRT inference engine for this sample
//!
//! \details This function is the main execution function of the sample. It allocates the buffer,
//! sets inputs and executes the engine.
//!
bool SampleOnnxMNIST::infer()
{
// 创建 RAII buffer 管理数据对象
samplesCommon::BufferManager buffers(mEngine);
auto context = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
if (!context)
{
return false;
}
// Read the input data into the managed buffers
assert(mParams.inputTensorNames.size() == 1);
if (!processInput(buffers))
{
return false;
}
// Memcpy from host input buffers to device input buffers
buffers.copyInputToDevice();
bool status = context->executeV2(buffers.getDeviceBindings().data());
if (!status)
{
return false;
}
// Memcpy from device output buffers to host output buffers
buffers.copyOutputToHost();
// Verify results
if (!verifyOutput(buffers))
{
return false;
}
return true;
}
|
其中processInput是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
//!
//! \brief Reads the input and stores the result in a managed buffer
//!
bool SampleOnnxMNIST::processInput(const samplesCommon::BufferManager& buffers)
{
const int inputH = mInputDims.d[2];
const int inputW = mInputDims.d[3];
// Read a random digit file
srand(unsigned(time(nullptr)));
std::vector<uint8_t> fileData(inputH * inputW);
mNumber = rand() % 10;
readPGMFile(locateFile(std::to_string(mNumber) + ".pgm", mParams.dataDirs), fileData.data(), inputH, inputW);
// Print an ascii representation
sample::gLogInfo << "Input:" << std::endl;
for (int i = 0; i < inputH * inputW; i++)
{
sample::gLogInfo << (" .:-=+*#%@"[fileData[i] / 26]) << (((i + 1) % inputW) ? "" : "\n");
}
sample::gLogInfo << std::endl;
float* hostDataBuffer = static_cast<float*>(buffers.getHostBuffer(mParams.inputTensorNames[0]));
for (int i = 0; i < inputH * inputW; i++)
{
hostDataBuffer[i] = 1.0 - float(fileData[i] / 255.0);
}
return true;
}
|
其中verifyOutput是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
//!
//! \brief Classifies digits and verify result
//!
//! \return whether the classification output matches expectations
//!
bool SampleOnnxMNIST::verifyOutput(const samplesCommon::BufferManager& buffers)
{
const int outputSize = mOutputDims.d[1];
float* output = static_cast<float*>(buffers.getHostBuffer(mParams.outputTensorNames[0]));
float val{0.0f};
int idx{0};
// Calculate Softmax
float sum{0.0f};
for (int i = 0; i < outputSize; i++)
{
output[i] = exp(output[i]);
sum += output[i];
}
sample::gLogInfo << "Output:" << std::endl;
for (int i = 0; i < outputSize; i++)
{
output[i] /= sum;
val = std::max(val, output[i]);
if (val == output[i])
{
idx = i;
}
sample::gLogInfo << " Prob " << i << " " << std::fixed << std::setw(5) << std::setprecision(4) << output[i]
<< " "
<< "Class " << i << ": " << std::string(int(std::floor(output[i] * 10 + 0.5f)), '*')
<< std::endl;
}
sample::gLogInfo << std::endl;
return idx == mNumber && val > 0.9f;
}
|
通常用下面的公式做精度比较:
1
2
3
4
5
|
y = model(x)
y_onnx = model_onnx(x)
# check the output against PyTorch
print(torch.max(torch.abs(y - y_trt)))
|
文章实现TensorRT自定义插件(plugin)自由!介绍的很详细。
- 可以模仿官方的
plugin库,添加自己的plugin后再相应的修改CMakeLists.txt,重新编译libnvinfer_plugin.so.7
- 模仿官方
plugin库的层级结构,生成一个新的.so,然后在自己的工程中调用它。
- 要创建一个plugin自定义类, 必须继承
IPluginV2Ext,IPluginV2IOExt,IPluginV2DynamicExt中的一个,并且重写其中的虚函数。
1
2
3
4
|
class FooPlugin : public IPluginV2IOExt
{
...override all pure virtual methods of IPluginV2IOExt with definitions for your plugin. Do not override the TRT_DEPRECATED methods.
};
|
- 要实现一个工厂类
FooPluginCreator,用于创建FooPlugin的实例
1
|
class MyCustomPluginCreator : public BaseCreator
|
IPluginCreator is a creator class for custom layers using which users can get plugin name, version, and plugin field parameters. It also provides methods to create the plugin object during the network build phase and deserialize it during inference.
Note: In versions of TensorRT prior to 6.0.1, you derived custom layers from IPluginV2 or IPluginV2Ext. While these APIs are still supported, we highly encourage you to move to IPluginV2IOExt or IPluginV2DynamicExt to be able to use all the new plugin functionalities.
TensorRT also provides the ability to register a plugin by calling REGISTER_TENSORRT_PLUGIN(pluginCreator) which statically registers the Plugin Creator to the Plugin Registry. During runtime, the Plugin Registry can be queried using the extern function getPluginRegistry(). The Plugin Registry stores a pointer to all the registered Plugin Creators and can be used to look up a specific Plugin Creator based on the plugin name and version.
然后通过REGISTER_TENSORRT_PLUGIN(pluginCreator)注册plugin(下文会涉及).
Note: To use TensorRT registered plugins in your application, the libnvinfer_plugin.so library must be loaded and all plugins must be registered. This can be done by calling initLibNvInferPlugins(void* logger, const char* libNamespace)() in your application code.
或者通过initLibNvInferPlugins(void* logger, const char* libNamespace)()来注册。(注册的方法二选一)
Using the Plugin Creator, the IPluginCreator::createPlugin() function can be called which returns a plugin object of type IPluginV2. This object can be added to the TensorRT network using addPluginV2() which creates and adds a layer to a network and then binds the layer to the given plugin. The method also returns a pointer to the layer (of type IPluginV2Layer), which can be used to access the layer or the plugin itself (via getPlugin()).
与静态shape类似,需要重写IPluginV2DynamicExt中的虚函数
1
2
3
4
|
class BarPlugin : public IPluginV2DynamicExt
{
...override virtual methods inherited from IPluginV2DynamicExt.
};
|
在main函数的网络定义中,加入plugin:
1
2
3
4
5
6
7
8
|
//网络的定义
...
//添加plugin
AddPlugin addPlugin(Weights{DataType::kFLOAT, &valueToAdd, 1});
ITensor *aInputTensor[] = {tensor};
//调用
tensor = network->addPluginV2(aInputTensor, 1, addPlugin)->getOutput(0);
network->markOutput(*tensor);
|
在AddPlugin.h中实现AddPlugin : public nvinfer1::IPluginV2IOExt和它的工厂类AddPluginCreator : public nvinfer1::IPluginCreator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
|
#include "NvInfer.h"
#include <iostream>
#include <cstring>
#include <assert.h>
using namespace std;
class AddPlugin: public nvinfer1::IPluginV2IOExt {
public:
//创建该插件时调用的构造函数,需要传递权重信息以及参数
AddPlugin(nvinfer1::Weights valueToAdd) {
m.valueToAdd = *(float *)valueToAdd.values;
}
//可以在反序列化时,调用这个构造函数
AddPlugin(const void *buffer, size_t length) {
memcpy(&m, buffer, sizeof(m));
}
//返回序列化时需要写多少字节到buffer中。
virtual size_t getSerializationSize() const override {
return sizeof(m);
}
//序列化
virtual void serialize(void *buffer) const override {
memcpy(buffer, &m, sizeof(m));
}
//拷贝函数,将这个plugin对象克隆一份给TensorRT的builder、network或者engine。(该方法会调用拷贝构造函数)
nvinfer1::IPluginV2IOExt* clone() const override {
return new AddPlugin(&m, sizeof(m));
}
//检查类型支持
//TensorRT调用此方法以判断pos索引的输入/输出是否支持inOut[pos].format和inOut[pos].type指定的格式/数据类型。
//如果插件支持inOut[pos]处的格式/数据类型,则返回true。如果是否支持取决于其他的输入/输出格式/数据类型,则插件可以使其结果取决于inOut[0..pos-1]中的格式/数据类型,该格式/数据类型将设置为插件支持的值。这个函数不需要检查inOut[pos + 1..nbInputs + nbOutputs-1],pos的决定必须仅基于inOut[0..pos]。
bool supportsFormatCombination(int pos, const nvinfer1::PluginTensorDesc* inOut, int nbInputs, int nbOutputs) const override {
switch(pos) {
case 0:
printf("inOut[0].type = %d, format[0]=%d\n", (int)inOut[0].type, (int)inOut[0].format);
return
((inOut[0].type == nvinfer1::DataType::kFLOAT || inOut[0].type == nvinfer1::DataType::kHALF) && inOut[0].format == nvinfer1::TensorFormat::kLINEAR)
|| (inOut[0].type == nvinfer1::DataType::kINT8 && inOut[0].format == nvinfer1::TensorFormat::kCHW4);
case 1:
printf("inOut[1].type = %d, format[1]=%d\n", (int)inOut[1].type, (int)inOut[1].format);
return inOut[0].format == inOut[1].format && inOut[0].type == inOut[1].type;
}
return false;
}
//返回的输出tensor数目
int getNbOutputs() const override {
return 1;
}
//定义返回的输出tensor维度
nvinfer1::Dims getOutputDimensions(int index, const nvinfer1::Dims* pInputDim, int nInputDim) override {
return pInputDim[0];
}
//返回结果的类型
nvinfer1::DataType getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const override {
return inputTypes[0] == nvinfer1::DataType::kFLOAT ? nvinfer1::DataType::kFLOAT : nvinfer1::DataType::kINT8;
}
//配置这个插件op,判断输入和输出类型数量是否正确。官方还提到通过这个配置信息可以告知TensorRT去选择合适的算法(algorithm)去调优这个模型。
virtual void configurePlugin(const nvinfer1::PluginTensorDesc* in, int nbInput, const nvinfer1::PluginTensorDesc* out, int nbOutput) override {
m.dataType = in[0].type;
m.inputDim = in[0].dims;
m.scale = in[0].scale;
printf("configurePlugin type=%d, m.scale=%f\n", (int)out[0].type, m.scale);
}
//我们需要在这里确定这个op需要多大的显存空间去运行,尽量不要自己取申请显存空间
//而是让Tensorrt官方接口传过来的workspace指针来管理显存空间
size_t getWorkspaceSize(int nMaxBatchSize) const override {return 0;}
//实际插件op的执行函数,我们自己实现的cuda操作就放到这里
//它的具体实现看下面的`AddPlugin.cu`
int enqueue(int nBatch, const void * const *inputs, void **outputs, void* workspace, cudaStream_t stream) override;
int initialize() override {return 0;}
void terminate() override {}
void destroy() override { delete this; }
//设置插件的namespace的名字
void setPluginNamespace(const char* szNamespace) override {}
//如果设置插件的namespace的名字,默认是""
const char* getPluginNamespace() const override {return "";}
const char* getPluginType() const override {return "AddPlugin";}
const char* getPluginVersion() const override {return "0";}
bool canBroadcastInputAcrossBatch(int inputIndex) const override {return false;}
bool isOutputBroadcastAcrossBatch(int outputIndex, const bool* inputIsBroadcasted, int nbInputs) const {return false;}
//如果这个op使用到了一些其他东西,例如cublas handle,可以直接借助TensorRT内部提供的cublas handle:
void attachToContext(cudnnContext* /*cudnn*/, cublasContext* /*cublas*/, nvinfer1::IGpuAllocator* /*allocator*/) {}
void detachFromContext() {}
private:
using nvinfer1::IPluginV2Ext::configurePlugin;
//插件中的权重、超参数定义在private里面
struct {
nvinfer1::DataType dataType;
nvinfer1::Dims inputDim;
float valueToAdd;
float scale;
} m;
};
class AddPluginCreator : public nvinfer1::IPluginCreator {
public:
//这个函数会被onnx-tensorrt的一个叫做TRT_PluginV2的转换op调用,这个op会读取onnx模型的data数据将其反序列化到network中。
nvinfer1::IPluginV2* deserializePlugin(const char* name, const void* serialData, size_t serialLength) override {
return new AddPlugin(serialData, serialLength);
}
const char* getPluginName() const override {return "AddPlugin";}
const char* getPluginVersion() const override {return "0";}
void setPluginNamespace(const char* szNamespace) override {}
const char* getPluginNamespace() const override {return "";}
//这个是成员变量,也会作为getFieldNames成员函数的返回类型。 PluginFieldCollection的主要作用是传递这个插件op所需要的权重和参数,在实际的engine推理过程中并不使用,而在parse中会用到(例如caffe2trt、onnx2trt)。
const nvinfer1::PluginFieldCollection* getFieldNames() override {
std::cout << __FUNCTION__ << std::endl;
return nullptr;
}
nvinfer1::IPluginV2* createPlugin(const char* name, const nvinfer1::PluginFieldCollection* fc) override {
std::cout << __FUNCTION__ << std::endl;
float valueToAdd = 0;
for (int i = 0; i < fc->nbFields; i++) {
if (!strcmp(fc->fields[i].name, "valueToAdd")) {
valueToAdd = *(float *)fc->fields[i].data;
}
}
return new AddPlugin({nvinfer1::DataType::kFLOAT, &valueToAdd, 1});
}
};
|
再看AddPlugin.cu中的算子实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
#include "AddPlugin.h"
#include "cuda_fp16.h"
#include <chrono>
#include <thread>
template<typename T>
__global__ void AddValue(T *pDst, T *pSrc, int n, T valueToAdd) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
if (x >= n) return;
pDst[x] = pSrc[x] + valueToAdd;
}
int AddPlugin::enqueue(int nBatch, const void * const *inputs, void **outputs, void* workspace, cudaStream_t stream) {
int n = nBatch;
for (int i = 0; i < m.inputDim.nbDims; i++) {
n *= m.inputDim.d[i];
}
printf("n=%d, nBatch=%d\n", n, nBatch);
if (m.dataType == nvinfer1::DataType::kFLOAT) {
std::cout << "Running fp32 kernel" << std::endl;
std::this_thread::sleep_for(20ms);
AddValue<<<(n + 1023) / 1024, 1024>>>((float *)outputs[0], (float *)inputs[0], n, m.valueToAdd);
} else if (m.dataType == nvinfer1::DataType::kHALF) {
std::cout << "Running fp16 kernel" << std::endl;
std::this_thread::sleep_for(10ms);
AddValue<<<(n + 1023) / 1024, 1024>>>((__half *)outputs[0], (__half *)inputs[0], n, (__half)m.valueToAdd);
} else {
std::cout << "Running int8 kernel" << std::endl;
std::this_thread::sleep_for(0ms);
float valueToAdd = m.valueToAdd / m.scale;
std::cout << "valueToAdd (int8 scaled): " << valueToAdd << ", " << (int)valueToAdd << std::endl;
AddValue<<<(n + 1023) / 1024, 1024>>>((int8_t *)outputs[0], (int8_t *)inputs[0], n, (int8_t)valueToAdd);
}
return 0;
}
//通过REGISTER_TENSORRT_PLUGIN注册plugin
REGISTER_TENSORRT_PLUGIN(AddPluginCreator);
|
同样地我们需要定义上述的AddPlugin.h和AddPlugin.cu,在mian函数中用DEFINE_BUILTIN_OP_IMPORTER注册算子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
DEFINE_BUILTIN_OP_IMPORTER(AddPlugin)
{
ASSERT(inputs.at(0).is_tensor(), ErrorCode::kUNSUPPORTED_NODE);
...
const std::string pluginName = "AddPlugin";
const std::string pluginVersion = "001";
// 这个f保存这个op需要的权重和参数,从onnx模型中获取
std::vector<nvinfer1::PluginField> f;
f.emplace_back("in_channel", &in_channel, nvinfer1::PluginFieldType::kINT32, 1);
f.emplace_back("weight", kernel_weights.values, nvinfer1::PluginFieldType::kFLOAT32, kernel_weights.count());
f.emplace_back("bias", bias_weights.values, nvinfer1::PluginFieldType::kFLOAT32, bias_weights.count);
// 这个从将plugin工厂中获取该插件,并且将权重和参数传递进去
nvinfer1::IPluginV2* plugin = importPluginFromRegistry(ctx, pluginName, pluginVersion, node.name(), f);
RETURN_FIRST_OUTPUT(ctx->network()->addPluginV2(tensors.data(), tensors.size(), *plugin));
}
|
TensorRT官方文档
onnx到trt的众多转换工具(模型库)
TensorRT Backend For ONNX
torch2trt
torch2trt_dynamic
TRTorch
一些官方开源的小工具,帮助我们更好地调试和可视化:
TensorRTTools
tensorrtx
trt-samples-for-hackathon-cn