本文主要记录在学习《GPU并行计算与CUDA编程》过程中的知识要点,并且把跑过的代码统一放在cmake工程里面。
关于cuda更具体的介绍,一个博客专题介绍的很好:
CUDA从入门到入门
对应的代码在: https://github.com/Tony-Tan/CUDA_Freshman

关于 cuda 的基础知识参考之前的文章:
最详细最新的内容,还看官网:CUDA C++ Programming Guide。
在CMake编译cuda程序,和编译一般的cpp程序几乎相同:
CMakeLists.txt编写如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
cmake_minimum_required(VERSION 3.8)
project(CUDA_MAT_MUL LANGUAGES CXX CUDA)
aux_source_directory(cuda_src CUDA_SRC_LIST)
aux_source_directory(cuda_head CUDA_INCLUDE_LIST)
include_directories(cuda_head)
add_library(cudaPractice ${CUDA_SRC_LIST} ${CUDA_INCLUDE_LIST})
target_compile_features(cudaPractice PUBLIC cxx_std_11)
#opencv
find_package(OpenCV 3.4.3 REQUIRED)
include_directories( ${OpenCV_INCLUDE_DIRS} )
add_executable(main main.cc)
target_link_libraries(main cudaPractice)
target_link_libraries(main ${OpenCV_LIBS})
|
目录结构如下所示:
 ◎ 目录结构
◎ 目录结构
add_library把cuda的源文件和头文件打包到静态库里面,然后target_compile_features和target_link_libraries调用打包的静态库。
 ◎ cpu和gpu的结构比较
◎ cpu和gpu的结构比较
- GPU,SM(流处理器),Kernel(核),thread block(线程块),线程
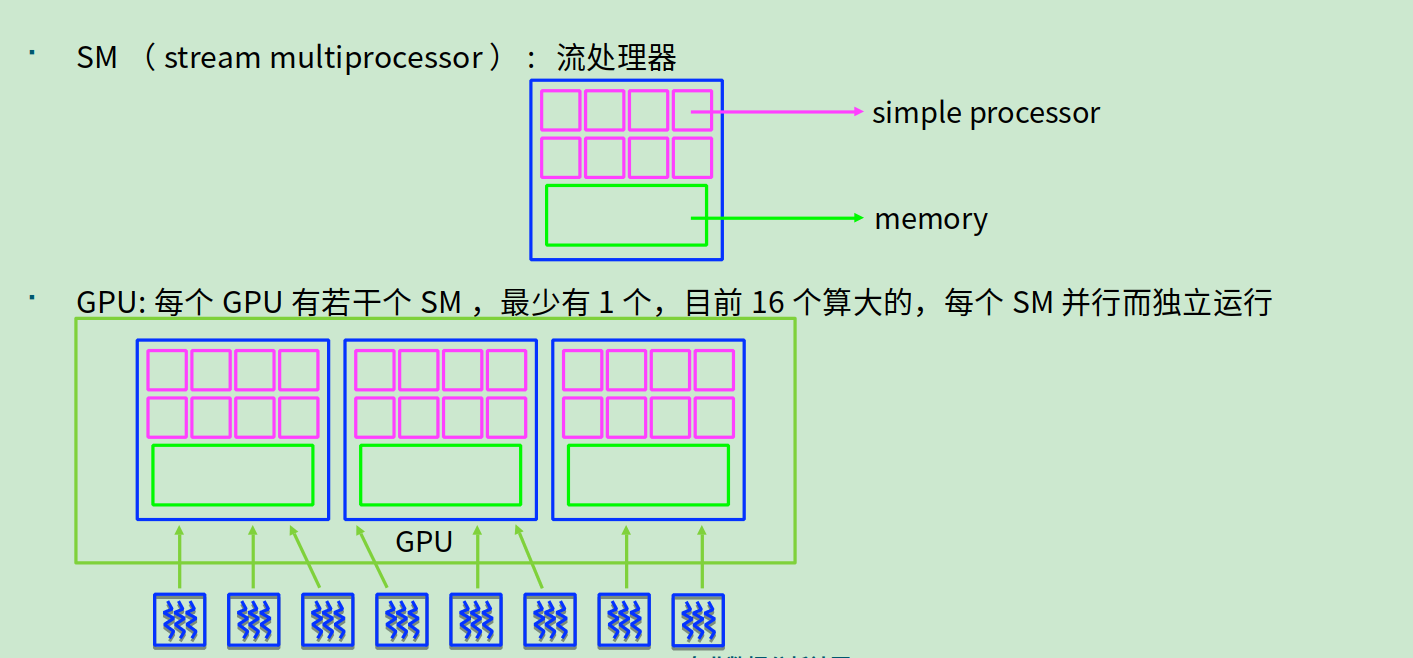 ◎ 流处理器
◎ 流处理器
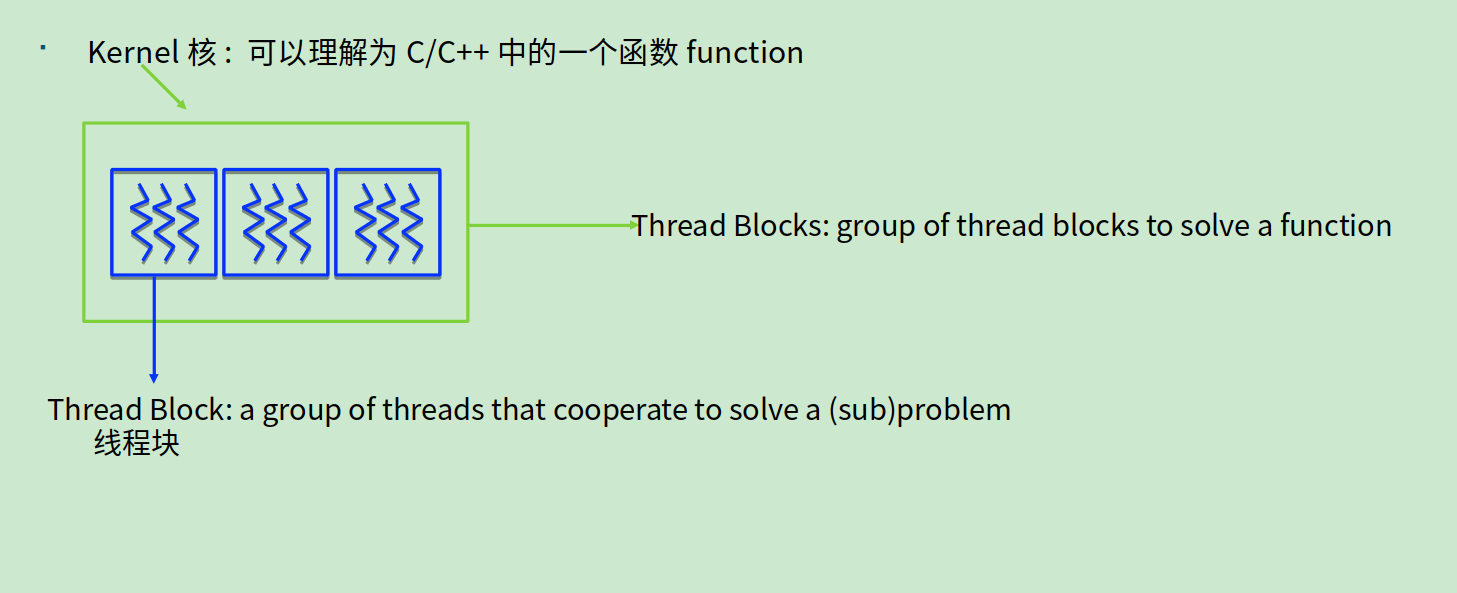 ◎ 核,线程块和线程
◎ 核,线程块和线程
- CPU的
ALU, Cache和Control单元的特点
ALU:CPU有强大的ALU(算术运算单元),它可以在很少的时钟周期内完成算术计算。
当今的CPU可以达到64bit 双精度。执行双精度浮点源算的加法和乘法只需要1~3个时钟周期。
CPU的时钟周期的频率是非常高的,达到1.532~3gigahertz(千兆HZ, 10的9次方).
Cache:大的缓存也可以降低延时。保存很多的数据放在缓存里面,当需要访问的这些数据,只要在之前访问过的,如今直接在缓存里面取即可。
Control:复杂的逻辑控制单元。
当程序含有多个分支的时候,它通过提供分支预测的能力来降低延时。
数据转发。 当一些指令依赖前面的指令结果时,数据转发的逻辑控制单元决定这些指令在pipeline中的位置并且尽可能快的转发一个指令的结果给后续的指令。这些动作需要很多的对比电路单元和转发电路单元。
- GPU的
ALU, Cache和Control单元的特点
ALU,Cache:GPU的特点是有很多的ALU和很少的cache. 缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面),获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。但是由于需要访问dram,自然会带来延时的问题。
Control:控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
GPU的虽然有dram延时,却有非常多的ALU和非常多的thread. 为了平衡内存延时的问题,我们可以中充分利用多的ALU的特性达到一个非常大的吞吐量的效果。尽可能多的分配多的Threads.通常来看GPU ALU会有非常重的pipeline就是因为这样。
CPU擅长逻辑控制,串行的运算。和通用类型数据运算不同,GPU擅长的是大规模并发计算,这也正是密码破解等所需要的。所以GPU除了图像处理,也越来越多的参与到计算当中来。
CUDA函数库
CUDA提供了几个较为成熟的高效函数库,程序员可以 直接调用这些库函数进行计算,因而大大简化了程序员 的工作量。其中最常用的包括:
CUFFT (利用CUDA进行傅里叶变换的函数库 )
CUBLAS (利用CUDA进行加速版本的完 整标准矩阵与向量的运算库 )
CUDPP (常用的并行操作函数库)
CUDNN (利用CUDA进行深度卷积神经网络,深度学习常用)
全部库:https://developer.nvidia.com/gpu-accelerated-libraries
__global__, __device__用来标识某个函数是设备代码而不是主机代码,而__host__表示主机代码(可以不写)。 主机/设备上的变量,在设备/主机上只可以访问而不能修改,不能在主机代码中用主机指针访问设备内存,反过来也一样,不能用设备指针访问主机内存。
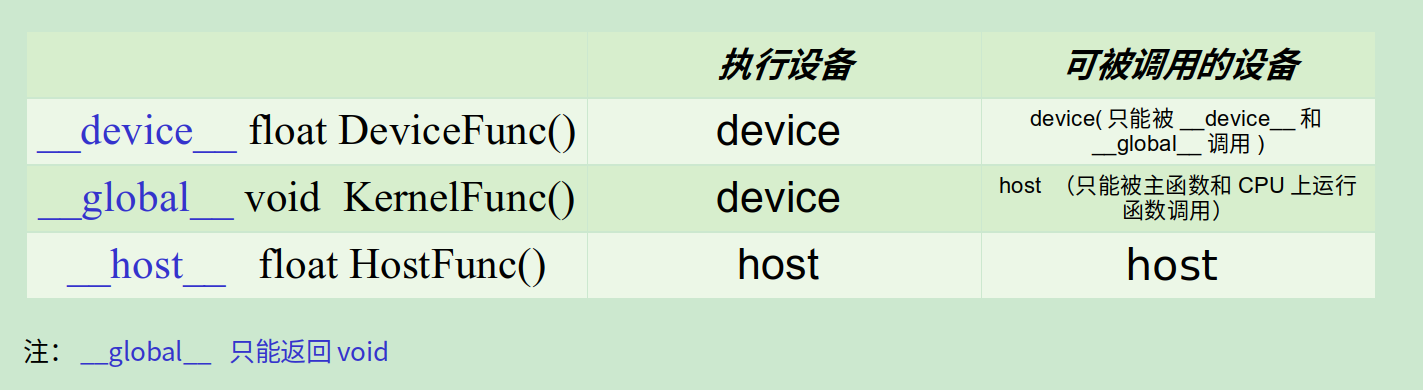 ◎ global, device, host
◎ global, device, host
-
cuda中threadIdx、blockIdx、blockDim和gridDim的使用
threadIdx是一个uint3类型,表示一个线程的索引。调用方法:(a.x, a.y, a.z)
blockIdx是一个uint3类型,表示一个线程块的索引,一个线程块中通常有多个线程。
blockDim是一个dim3类型,表示线程块的大小。
gridDim是一个dim3类型,表示网格的大小,一个网格中通常有多个线程块。
一维线程的使用:
1
2
3
4
5
6
7
8
|
__global__ void add_kernel(double *a, double *b, double *c) {
//block id
int tid = blockIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
|
1
2
3
4
5
6
7
8
9
10
11
|
err1 = cudaMalloc((void**)&dev_a, N * sizeof(double));
err2 = cudaMalloc((void**)&dev_b, N * sizeof(double));
err3 = cudaMalloc((void**)&dev_c, N * sizeof(double));
//表示 N 个block, 每个block分配 1个 thread
add_kernel << <N, 1 >> > (dev_a, dev_b, dev_c);////在GPU上相加操作
////用完设备指针要释放
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
|
二维block的使用:
1
2
3
4
5
6
|
__global__ void kernel(unsigned char *ptr) {
int x = blockIdx.x;
int y = blockIdx.y;
int offset = x + y * gridDim.x;
//...
}
|
1
2
3
4
5
6
7
8
|
unsigned char *dev_bitmap;
HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, bitmap.image_size()));
dim3 grid(DIM1, DIM2); ////实际上是DIM1*DIM2*1的三维线程格
//三维grid, 1个thread
kernel << <grid, 1 >> > (dev_bitmap);
HANDLE_ERROR(cudaFree(dev_bitmap));
|
更多自由搭配:(1/2/3维度block)*(1/2/3维度thread):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
|
//thread 1D
__global__ void testThread1(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = b[i] - a[i];
}
//thread 2D
__global__ void testThread2(int *c, const int *a, const int *b)
{
int i = threadIdx.x + threadIdx.y*blockDim.x;
c[i] = b[i] - a[i];
}
//thread 3D
__global__ void testThread3(int *c, const int *a, const int *b)
{
int i = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
c[i] = b[i] - a[i];
}
//block 1D
__global__ void testBlock1(int *c, const int *a, const int *b)
{
int i = blockIdx.x;
c[i] = b[i] - a[i];
}
//block 2D
__global__ void testBlock2(int *c, const int *a, const int *b)
{
int i = blockIdx.x + blockIdx.y*gridDim.x;
c[i] = b[i] - a[i];
}
//block 3D
__global__ void testBlock3(int *c, const int *a, const int *b)
{
int i = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
c[i] = b[i] - a[i];
}
//block-thread 1D-1D
__global__ void testBlockThread1(int *c, const int *a, const int *b)
{
int i = threadIdx.x + blockDim.x*blockIdx.x;
c[i] = b[i] - a[i];
}
//block-thread 1D-2D
__global__ void testBlockThread2(int *c, const int *a, const int *b)
{
int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;
int i = threadId_2D+ (blockDim.x*blockDim.y)*blockIdx.x;
c[i] = b[i] - a[i];
}
//block-thread 1D-3D
__global__ void testBlockThread3(int *c, const int *a, const int *b)
{
int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockIdx.x;
c[i] = b[i] - a[i];
}
//block-thread 2D-1D
__global__ void testBlockThread4(int *c, const int *a, const int *b)
{
int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;
int i = threadIdx.x + blockDim.x*blockId_2D;
c[i] = b[i] - a[i];
}
//block-thread 3D-1D
__global__ void testBlockThread5(int *c, const int *a, const int *b)
{
int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
int i = threadIdx.x + blockDim.x*blockId_3D;
c[i] = b[i] - a[i];
}
//block-thread 2D-2D
__global__ void testBlockThread6(int *c, const int *a, const int *b)
{
int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;
int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;
int i = threadId_2D + (blockDim.x*blockDim.y)*blockId_2D;
c[i] = b[i] - a[i];
}
//block-thread 2D-3D
__global__ void testBlockThread7(int *c, const int *a, const int *b)
{
int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
int blockId_2D = blockIdx.x + blockIdx.y*gridDim.x;
int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockId_2D;
c[i] = b[i] - a[i];
}
//block-thread 3D-2D
__global__ void testBlockThread8(int *c, const int *a, const int *b)
{
int threadId_2D = threadIdx.x + threadIdx.y*blockDim.x;
int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
int i = threadId_2D + (blockDim.x*blockDim.y)*blockId_3D;
c[i] = b[i] - a[i];
}
//block-thread 3D-3D
__global__ void testBlockThread9(int *c, const int *a, const int *b)
{
int threadId_3D = threadIdx.x + threadIdx.y*blockDim.x + threadIdx.z*blockDim.x*blockDim.y;
int blockId_3D = blockIdx.x + blockIdx.y*gridDim.x + blockIdx.z*gridDim.x*gridDim.y;
int i = threadId_3D + (blockDim.x*blockDim.y*blockDim.z)*blockId_3D;
c[i] = b[i] - a[i];
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
//testThread1<<<1, size>>>(dev_c, dev_a, dev_b);
//uint3 s;s.x = size/5;s.y = 5;s.z = 1;
//testThread2 <<<1,s>>>(dev_c, dev_a, dev_b);
//uint3 s; s.x = size / 10; s.y = 5; s.z = 2;
//testThread3<<<1, s >>>(dev_c, dev_a, dev_b);
//testBlock1<<<size,1 >>>(dev_c, dev_a, dev_b);
//uint3 s; s.x = size / 5; s.y = 5; s.z = 1;
//testBlock2<<<s, 1 >>>(dev_c, dev_a, dev_b);
//uint3 s; s.x = size / 10; s.y = 5; s.z = 2;
//testBlock3<<<s, 1 >>>(dev_c, dev_a, dev_b);
//testBlockThread1<<<size/10, 10>>>(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 1; s1.z = 1;
//uint3 s2; s2.x = 10; s2.y = 10; s2.z = 1;
//testBlockThread2 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 1; s1.z = 1;
//uint3 s2; s2.x = 10; s2.y = 5; s2.z = 2;
//testBlockThread3 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = 10; s1.y = 10; s1.z = 1;
//uint3 s2; s2.x = size / 100; s2.y = 1; s2.z = 1;
//testBlockThread4 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = 10; s1.y = 5; s1.z = 2;
//uint3 s2; s2.x = size / 100; s2.y = 1; s2.z = 1;
//testBlockThread5 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 10; s1.z = 1;
//uint3 s2; s2.x = 5; s2.y = 2; s2.z = 1;
//testBlockThread6 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = size / 100; s1.y = 5; s1.z = 1;
//uint3 s2; s2.x = 5; s2.y = 2; s2.z = 2;
//testBlockThread7 << <s1, s2 >> >(dev_c, dev_a, dev_b);
//uint3 s1; s1.x = 5; s1.y = 2; s1.z = 2;
//uint3 s2; s2.x = size / 100; s2.y = 5; s2.z = 1;
//testBlockThread8 <<<s1, s2 >>>(dev_c, dev_a, dev_b);
uint3 s1; s1.x = 5; s1.y = 2; s1.z = 2;
uint3 s2; s2.x = size / 200; s2.y = 5; s2.z = 2;
testBlockThread9<<<s1, s2 >>>(dev_c, dev_a, dev_b);
//或者:
dim3 blocks(DIM/16,DIM/16,1); ////二维线程块
dim3 threads(16,16,1); ////二维线程
func_kernel<<<blocks,threads>>>(参数);
|
注意的是 blockDim.x和 gridDim.x确实有一个物理上的最大值,但在使用时的大小是由在代码中的设定决定的,比如下面的:
1
2
3
4
5
6
7
8
9
10
11
|
__global__ void add_kernel(double *a, double *b, double *c) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x;
}
}
add_kernel << < 128, 128 >> > (dev_a, dev_b, dev_c);////在GPU上相加操作
|
blockDim.x和gridDim.x都为128, 128,确实这样是合理的,它让我们可以固定具体使用多少的thread,而不因为数据扩增而导致出现异常。同理地,合理的设置使得blockDim.x和gridDim.x逼近gpu的计算上限,可以充分利用gpu的计算能力。
- 在设备代码上定义结构体(类)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
struct cuComplex {
float r;
float i;
__device__ cuComplex(float a, float b) :r(a), i(b) {}
__device__ float magnitude2(void) {
return r*r + i*i;
} ////返回复数的模的平方
__device__ cuComplex operator*(const cuComplex& a) {
return cuComplex(r*a.r - i*a.i, i*a.r + r*a.i);
}
__device__ cuComplex operator+(const cuComplex& a) {
return cuComplex(r + a.r, i + a.i);
}
};
|
可以看到,和常用的C++代码,区别也只在于函数定义是否有__device__标识符。
GPU编程3--GPU内存深入了解这篇文章讲的很清楚。
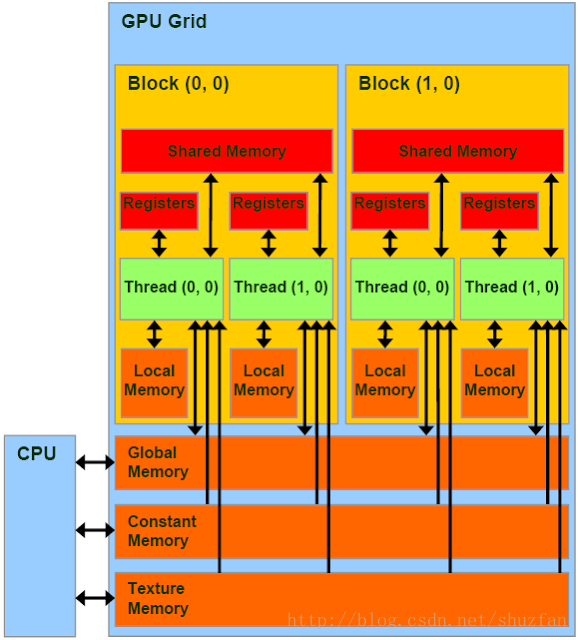
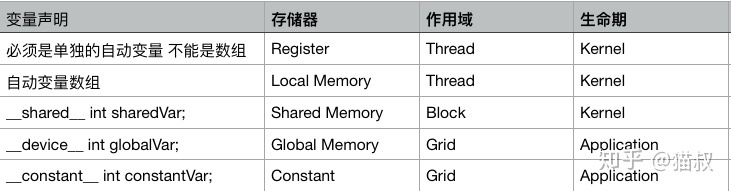
cuda中有寄存器内存,局部内存,共享内存,常量内存,纹理内存,全局内存。寄存器内存用于定义线程专属私有变量。当私有变量申请大小溢出时,自动转为局部内存。当在核函数里面申请局部数组时,自动称为局部内存。
- 共享内存
共享内存(shared memory,SMEM)是GPU的一个关键部分,物理层面,每个SM都有一个小的内存池,这个线程池被次SM上执行的线程块中的所有线程所共享。共享内存使同一个线程块中可以相互协同,便于片上的内存可以被最大化的利用,降低回到全局内存读取的延迟。
共享内存是被我们用代码控制的,这也是是他称为我们手中最灵活的优化武器。
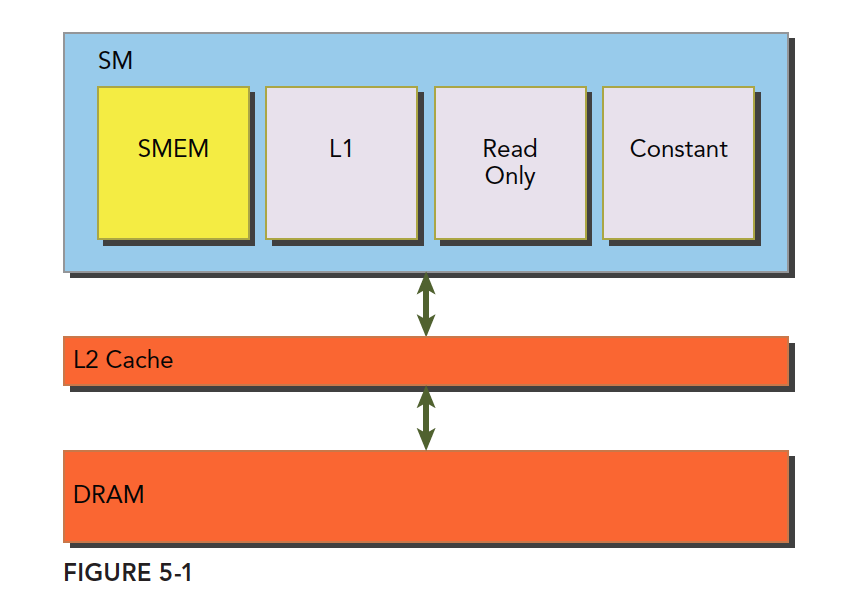
一级缓存,二级缓存,共享内存,以及只读和常量缓存,他们的关系如下图:
 ◎ 一级缓存,二级缓存,共享内存,以及只读和常量缓存
◎ 一级缓存,二级缓存,共享内存,以及只读和常量缓存
可以看到, 共享内存(SMEM), 一级缓存, 只读缓存和常量缓存更接近SM计算核心,有更低的访问延迟和传输带宽。
将线程块分解为线程的目的,除了物理设备上线程块最大数目的限制,还有一个原因是 CUDA C支持共享内存。对于GPU上的每一个线程块,编译器都为该共享变量创建一个副本,而线程块中的每一个线程共享这块内存。由于共享内存驻留在物理GPU上而不是GPU之外的系统内存中,访问共享内存的延迟要远低于访问普通内缓存区的延迟。
利用共享内存实现内积(dot):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
__global__ void dot(float *a, float *b, float *c) {
__shared__ float cache[threadsPerBlock]; ////共享内存缓存区(驻留在物理GPU上),编译器为每一个线程块生成一个共享变量的副本。同一线程块中的每个线程共享这块内存。
int tid = threadIdx.x + blockIdx.x * blockDim.x; ////索引偏置
int cacheIndex = threadIdx.x; ////由于每一个线程块都具有一个共享内存的副本,故共享内存的索引就是该线程块上的线程索引。
float temp = 0;
while (tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// set the cache values
cache[cacheIndex] = temp; ////每个线程处理的数据,相加放在对应的共享内存区域中。
// synchronize threads in this block
__syncthreads(); ////线程同步,当所有的线程都执行完以上操作时,才能继续执行下一步。
// for reductions, threadsPerBlock must be a power of 2
// because of the following code
////归约,将共享内存区域每一个储存的值相加起来,由于规约每次迭代数量减半,要求 threadsPerBlock 是2 的指数倍。
int i = blockDim.x / 2;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads(); ////线程同步。同样地,执行下一次规约迭代前,必须确保所有线程都已经执行完上面相加的操作。
i /= 2;
}
if (cacheIndex == 0)
c[blockIdx.x] = cache[0]; ////把一个线程块中的最后计算得到的相加值返还给全局变量。
}
|
若申请blocksPerGrid个block, 则会在gpu上创建blocksPerGrid个共享内存副本。
共享内存和block同生命周期。
1
2
|
dot << <blocksPerGrid, threadsPerBlock >> >(dev_a, dev_b,
dev_partial_c);
|
- 常量内存
常量内存用于保存在核函数执行期间不会发生变化的数据,由于GPU的性能瓶颈通常不在于芯片的数学吞吐能力,而在于芯片的内存带宽,合理利用常量内存能有效减小内存的带宽的消耗。常量内存存在于核函数之外,在kernel函数外声明,即常量内存存在于内存中,并不在片上,常量内容的访问速度也是很快的,这是因为每个SM都有专用的常量内存缓存,会把片外的常量读取到缓存中;对所有的核函数都可见,在Host端进行初始化后,核函数不能再修改。
写法:
1
|
__constant__ Sphere s[num]
|
对于常量内存,不需要再用 cudaMalloc() 或者 cudaFree() 来申请或释放内存空间,编译器会自动为这个数组提交一个固定的大小。
cudaMemcpy() 会将主机内存复制到全局内存,而cudaMemcpyToSymbol() 会将主机内存复制到常量内存。
常量内存为什么有效:
-
对常量内存的单次操作可以广播到其他临近线程,范围为半个线程束(Wrap)。
-
常量内存的数据将缓存起来,因此对相同地址的连续读操作不会产生额外的内存通信量。
在CUDA架构中,线程束是指包含32个线程的集合,这个线程集合被“编织”在一起并且以“步调一致”的形式执行,在程序的每一行,线程束中的每个线程都在不同的数据中执行相同的操作。当这半个线程束读取常量内存相同地址时,才可以大幅度提升性能,否则,这半个线程束的请求会被串行化,在这个情况下性能反而会降低。
常量内存有两个特性,一个是高速缓存,另一个是它支持将单个值广播到线程束中的每个线程。但要注意的是,对于那些数据不太集中或者数据重用率不高的内存访问,尽量不要使用常量内存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
#define SPHERES 20
__constant__ Sphere s[SPHERES];
int main(void) {
// allocate temp memory, initialize it, copy to constant
// memory on the GPU, then free our temp memory
Sphere *temp_s = (Sphere*)malloc(sizeof(Sphere) * SPHERES);
for (int i = 0; i<SPHERES; i++) {
temp_s[i].r = rnd(1.0f);
temp_s[i].g = rnd(1.0f);
temp_s[i].b = rnd(1.0f);
temp_s[i].x = rnd(1000.0f) - 500;
temp_s[i].y = rnd(1000.0f) - 500;
temp_s[i].z = rnd(1000.0f) - 500;
temp_s[i].radius = rnd(100.0f) + 20;
}
//用cudaMemcpyToSymbol拷贝到常量内存
HANDLE_ERROR(cudaMemcpyToSymbol(s, temp_s,
sizeof(Sphere) * SPHERES));
free(temp_s);
}
|
- 纹理内存
同常量内存一样,纹理内存(Texture Memory)也是一种只读内存。 之所以称之为 “纹理”,是因为最初是为图形应用设计的。 当程序中存在大量局部空间操作时,纹理内存可以提高性能。
纹理内存的优势:
1.它们是被缓存的,如果它们在texture fetch 中将提供更高的带宽
2.它们不会像全局或常驻内存读取时受内存访问模式的约束
3.寻址计算时的延迟更低,从而提高随机访问数据时的性能
4.在一个操作中,包装的数据可以通过广播到不同的变量中
5.8-bit和16-bit的整型输入数据可以被转换成在范围[0.0,1.0]或[-1.0,1.0]的浮点数
- 全局内存
全局内存,就是我们常说的显存,就是GDDR的空间,全局内存中的变量,只要不销毁,生命周期和应用程序是一样的。
在访问全局内存时,要求是对齐的,也就是一次要读取指定大小(32、64、128)整数倍字节的内存,数据对齐就意味着传输效率降低,比如我们想读33个字节,但实际操作中,需要读取64字节的空间。
cudaMemcpy() 会将主机内存复制到全局内存,而cudaMemcpyToSymbol() 会将主机内存复制到常量内存。
- 避免线程发散
要避免线程发散的程序:
若将:
1
2
3
4
5
6
|
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
|
改为:
1
2
3
4
5
6
7
8
|
while (i != 0) {
if (cacheIndex < i)
{
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
}
i /= 2;
}
|
则是错误的,因为不能保证cacheIndex < i对每个线程都成立。
尽量也要避免在kernel做条件判断,使得不同线程可能执行不同操作。
- 要关注代码性能
使用Even测量代码性能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
*****************
在GPU上执行一些工作(包括前后的设备内存复制)
*****************
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime,start, stop);
printf("Time to generate: %3.1f ms\n", elapsedTime);
cudaEventDestroy(start);
cudaEventDestroy(stop);
|
-
所有在同一个线程块上的线程必然会在同一时间运行在同一个SM上
-
同一个内核的所有线程块必然会全部完成了后,才会运行下一个内核
-
线程同步
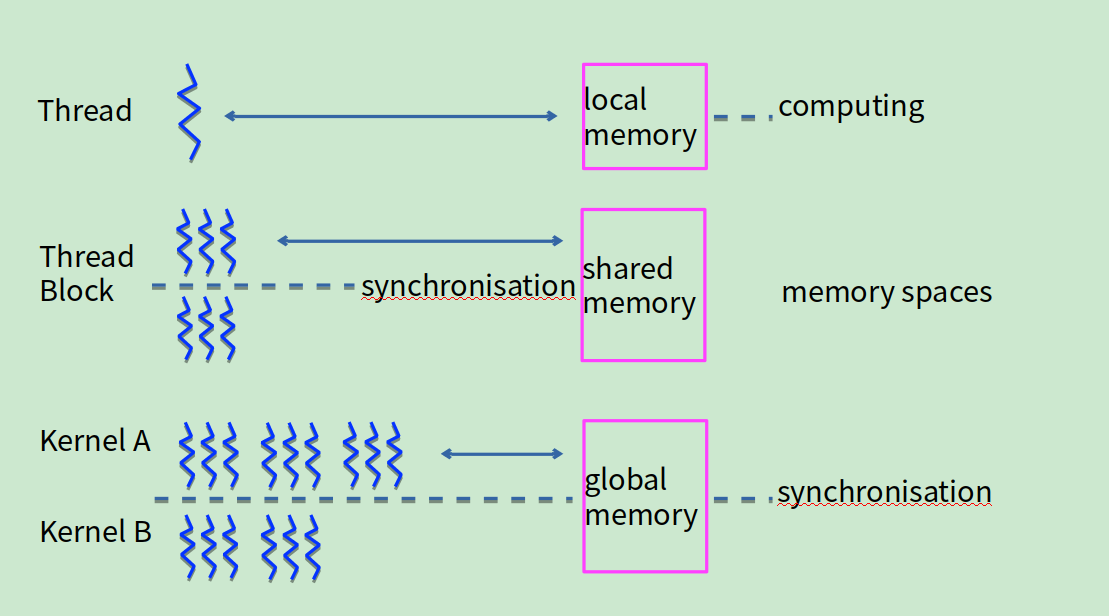
不同的线程在共享和全局内存中读写数据需要有先后的控制,所以引入了同步性的概念。
 ◎ 同步
◎ 同步
_syncthreads():线程块内线程同步
_threadfence(): 一个线程调用__threadfence后,该线程在该语句前对全局存储器或共享存储器的访问已经全部完成,执行结果对grid中的所有线程可见。
_threadfence_block(): 一个线程调用__threadfence_block后,该线程在该语句前对全局存储器或者共享存储器的访问已经全部完成,执行结果对block中的所有线程可见。
以上两个函数的重要作用是,及时通知其他线程,全局内存或者共享内存内的结果已经读入或写入完成了。
- 最大化计算强度
意味着要最大化每个线程的计算量和最小化每个线程的内存读取速度
- 原子操作
对于有很多线程需要同时读取或写入相同的内存时,保证同一时间只有一个线程能进行操作。
只支持某些运算(加、减、最小值、异或运算等,不支持求余和求幂等)和数据类型(整型)
 ◎ 各种原子操作
◎ 各种原子操作
举个例子,假设我们想要用GPU统计“char data_0[32] = {1,0, … ,1}”这个数组中“0”和“1”的个数并写入“int counter[2]”中。
如果我们不使用原子操作,直接在核函数中这样写:
1
2
3
4
5
6
7
8
9
10
11
|
extern "C" __global__ void kernel_func(int * counter, char * data_0)
{
// 计算线程号
unsigned int block_index = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
unsigned int thread_index = block_index * blockDim.x * blockDim.y * blockDim.z + \
threadIdx.x + threadIdx.y * blockDim.x + threadIdx.z * blockDim.x * blockDim.y;
// 统计结果
int value = data_0[thread_index];
counter[value] ++;
}
|
我们会发现结果是“counter[2] = {1, 1}”,这显然不是正确的结果。
正确的写法是:
1
2
3
4
5
6
7
8
9
10
11
|
extern "C" __global__ void kernel_func(int * counter, char * data_0)
{
// 计算线程号
unsigned int block_index = blockIdx.x + blockIdx.y * gridDim.x + blockIdx.z * gridDim.x * gridDim.y;
unsigned int thread_index = block_index * blockDim.x * blockDim.y * blockDim.z + \
threadIdx.x + threadIdx.y * blockDim.x + threadIdx.z * blockDim.x * blockDim.y;
// 统计结果
int value = data_0[thread_index];
atomicAdd(&counter[value], 1);
}
|
- CUDA流Streams
用到CUDA的程序一般需要处理海量的数据,内存带宽经常会成为主要的瓶颈。在Stream的帮助下,CUDA程序可以有效地将内存读取和数值运算并行,从而提升数据的吞吐量。
cudaStreams 有效的原因, 在nvidia gpu中:
数据拷贝和数值计算可以同时进行。
两个方向的拷贝可以同时进行(GPU到CPU,和CPU到GPU),数据如同行驶在双向快车道。
这样,使用一个Stream搬移大量数据,由于内存带宽有限,速度可能没有把数据切块,用多个Streams来搬移的速度块。当然,这是在gpu的运算单元没有全被占用的情况下是成立的。
定义流:cudaStream_t s1;
创建流:cudaStreamCreate(&s1);
销毁流:cudaStreamDestory(s1);
使用八个Streams来优化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
uint8_t* bgraBuffer;
uint8_t* yuvBuffer;
uint8_t* deviceBgraBuffer;
uint8_t* deviceYuvBuffer;
const int dataSizeBgra = 7680 * 4320 * 4;
const int dataSizeYuv = 7680 * 4320 * 3;
cudaMallocHost(&bgraBuffer, dataSizeBgra);
cudaMallocHost(&yuvBuffer, dataSizeYuv);
cudaMalloc(&deviceBgraBuffer, dataSizeBgra);
cudaMalloc(&deviceYuvBuffer, dataSizeYuv);
//随机生成8K的BGRA图像
GenerateBgra8K(bgraBuffer, dataSizeBgra);
//Stream的数量,这里用8个
const int nStreams = 8;
//Stream的初始化
cudaStream_t streams[nStreams];
for (int i = 0; i < nStreams; i++) {
cudaStreamCreate(&streams[i]);
}
//计算每个Stream处理的数据量。这里只是简单将数据分成8等分
//这里不会出现不能整除的情况,但实际中要小心
int brgaOffset = 0;
int yuvOffset = 0;
const int brgaChunkSize = dataSizeBgra / nStreams;
const int yuvChunkSize = dataSizeYuv / nStreams;
//这个循环依次启动 nStreams 个 Stream
for(int i=0; i<nStreams; i++)
{
brgaOffset = brgaChunkSize*i;
yuvOffset = yuvChunkSize*i;
//CPU到GPU的数据拷贝(原始数据),Stream i
cudaMemcpyAsync( deviceBgraBuffer+brgaOffset,
bgraBuffer+brgaOffset,
brgaChunkSize,
cudaMemcpyHostToDevice,
streams[i] );
//数值计算,Stream i
convertPixelFormat<<<4096, 1024, 0, streams[i]>>>(
deviceBgraBuffer+brgaOffset,
deviceYuvBuffer+yuvOffset,
brgaChunkSize/4 );
//GPU到CPU的数据拷贝(计算结果),Stream i
cudaMemcpyAsync( yuvBuffer+yuvOffset,
deviceYuvBuffer+yuvOffset,
yuvChunkSize,
cudaMemcpyDeviceToHost,
streams[i] );
}
//等待所有操作完成
cudaDeviceSynchronize();
cudaFreeHost(bgraBuffer);
cudaFreeHost(yuvBuffer);
cudaFree(deviceBgraBuffer);
cudaFree(deviceYuvBuffer);
|
详细代码看CUDA随笔之Stream的使用, 讲的很详细。
可以参考cuda_practice ,熟悉opencv和cuda联合编程的几个例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
/****************************1. 并行编程的基础知识***********************************/
//1. hello cuda
showhello();
//2. 矩阵相乘
showMatMul();
//3. 求平方
showsquare();
//4. 多数之和 输入参数0:使用全局内存 输入参数1:使用共享内存
showreduce(0);
//5. 数组扫描 更新数组,每一个数组的值是前面所有遍历过的数组的值之和 输入参数0:使用全局内存 输入参数1:使用共享内存
showscan(1);
//上面两个例子的global memory 都比 share memory 的时间小,不太懂为什么,是跑的数据量比较小吗
//6. 分段直方图统计 输入参数0:错误示范 输入参数1:不分段,适用于bin数比较多的情况 输入参数2:分段,适用于bin数比较少的情况
//分段直方图思想:假设开的线程数是THREADS_COUNT,直方图分组的数是BIN_COUNT;
//每个线程不只处理一个数据,而是平均地处理ARRAY_SIZE/THREADS_COUNT个数据。
//这时需要创建一个THREADS_COUNT×BIN_COUNT×sizeof(int)的共享内存,每个线程处理ARRAY_SIZE/THREADS_COUNT个数据,然后把结果放在
//BIN_COUNT×sizeof(int)的共享内存里面;将所有数据处理完后再做一次reduce即可。
//速度比不分段的慢,但开的线程很少,节省资源
showhisto(1);
/*****************************2. 图像处理中的并行编程基础**********************************/
//7. 彩色图转灰度图
showrgb2grey();
//8. 均值滤波
showblur();
//9. 图像翻转
showreverse();
|