在实践中,添加过多的层后训练误差往往不降反升。即使利用批量归一化带来的数值稳定性使训练深层模型更加容易,该问题仍然存在。针对这一问题,何恺明等人提出了残差网络(ResNet)。本节记录残差网络和它的变式:稠密网络。摘自《动手学深度学习》
残差网络(ResNet)
网络模型
残差块
下图的右图是ResNet的基础块,即残差块(residual block)。在残差块中,输入可通过跨层的数据线路更快地向前传播。
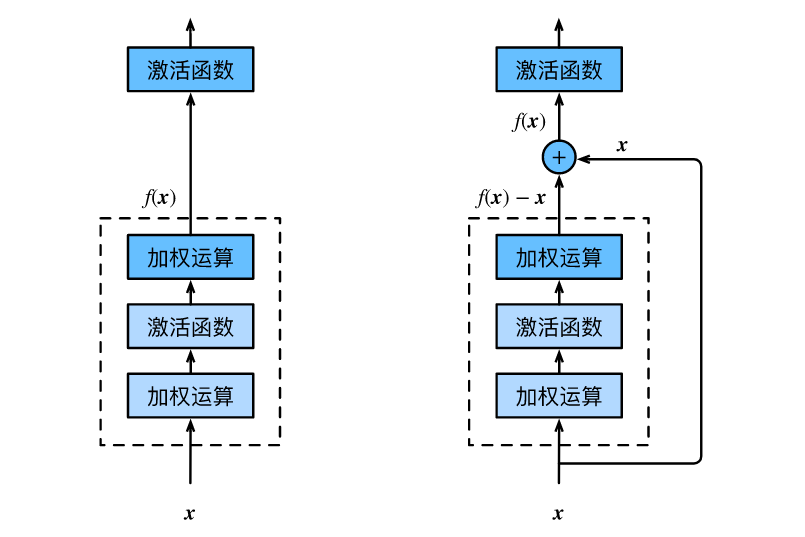 ResNet沿用了VGG全3×3卷积层的设计。残差块里首先有2个有相同输出通道数的3×3卷积层。每个卷积层后接一个批量归一化层和ReLU激活函数。然后我们将输入跳过这两个卷积运算后直接加在最后的ReLU激活函数前。这样的设计要求两个卷积层的输出与输入形状一样,从而可以相加。如果想改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后再做相加运算。
ResNet沿用了VGG全3×3卷积层的设计。残差块里首先有2个有相同输出通道数的3×3卷积层。每个卷积层后接一个批量归一化层和ReLU激活函数。然后我们将输入跳过这两个卷积运算后直接加在最后的ReLU激活函数前。这样的设计要求两个卷积层的输出与输入形状一样,从而可以相加。如果想改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后再做相加运算。
ResNet模型
ResNet的前两层跟之前介绍的GoogLeNet中的一样:在输出通道数为64、步幅为2的7×7卷积层后接步幅为2的3×3的最大池化层。不同之处在于ResNet每个卷积层后增加的批量归一化层。
GoogLeNet在后面接了4个由Inception块组成的模块。ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。第一个模块的通道数同输入通道数一致。由于之前已经使用了步幅为2的最大池化层,所以无须减小高和宽。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
python实现
|
|
稠密连接网络(DenseNet)
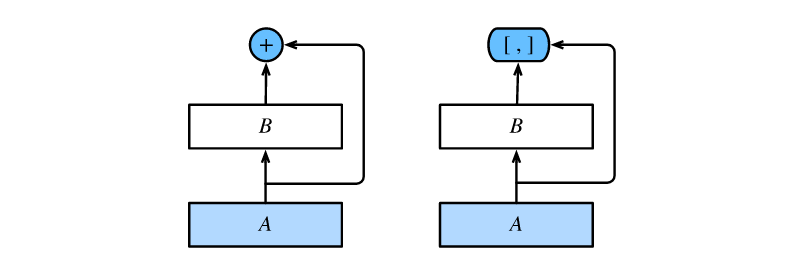 图中将部分前后相邻的运算抽象为模块𝐴和模块𝐵。与ResNet的主要区别在于,DenseNet里模块𝐵的输出不是像ResNet那样和模块𝐴的输出相加,而是在通道维上连结。这样模块𝐴的输出可以直接传入模块𝐵后面的层。在这个设计里,模块𝐴直接跟模块𝐵后面的所有层连接在了一起。这也是它被称为“稠密连接”的原因。
图中将部分前后相邻的运算抽象为模块𝐴和模块𝐵。与ResNet的主要区别在于,DenseNet里模块𝐵的输出不是像ResNet那样和模块𝐴的输出相加,而是在通道维上连结。这样模块𝐴的输出可以直接传入模块𝐵后面的层。在这个设计里,模块𝐴直接跟模块𝐵后面的所有层连接在了一起。这也是它被称为“稠密连接”的原因。
DenseNet的主要构建模块是稠密块(dense block)和过渡层(transition layer)。前者定义了输入和输出是如何连结的,后者则用来控制通道数,使之不过大。
模型结构
稠密块
DenseNet使用了ResNet改良版的“批量归一化、激活和卷积”结构。稠密块由多个conv_block组成,每块使用相同的输出通道数。但在前向计算时,我们将每块的输入和输出在通道维上连结。
过渡层
由于每个稠密块都会带来通道数的增加,使用过多则会带来过于复杂的模型。过渡层用来控制模型复杂度。它通过1×1卷积层来减小通道数,并使用步幅为2的平均池化层减半高和宽,从而进一步降低模型复杂度。
DenseNet模型
DenseNet首先使用同ResNet一样的单卷积层和最大池化层。类似于ResNet接下来使用的4个残差块,DenseNet使用的是4个稠密块。同ResNet一样,我们可以设置每个稠密块使用多少个卷积层。 ResNet里通过步幅为2的残差块在每个模块之间减小高和宽。这里我们则使用过渡层来减半高和宽,并减半通道数。最后,同ResNet一样,最后接上全局池化层和全连接层来输出。
python实现
|
|