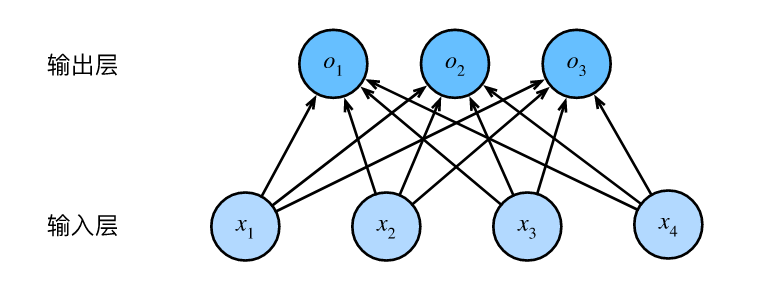
 softmax回归其实是用来做分类的模型,和线性回归不同,softmax回归的输出单元从一个变成了多个,且引入了softmax运算使输出更适合离散值的预测和训练。摘自《动手学深度学习》
softmax回归其实是用来做分类的模型,和线性回归不同,softmax回归的输出单元从一个变成了多个,且引入了softmax运算使输出更适合离散值的预测和训练。摘自《动手学深度学习》
softmax回归模型概念
softmax回归跟线性回归一样将输入特征与权重做线性叠加。与线性回归的一个主要不同在于,softmax回归的输出值个数等于标签里的类别数。
数学模型
$$ \begin{aligned} o_1 &= x_1 w_{11} + x_2 w_{21} + x_3 w_{31} + x_4 w_{41} + b_1,\\ o_2 &= x_1 w_{12} + x_2 w_{22} + x_3 w_{32} + x_4 w_{42} + b_2,\\ o_3 &= x_1 w_{13} + x_2 w_{23} + x_3 w_{33} + x_4 w_{43} + b_3. \end{aligned} $$
若要输出是离散的预测,一个方法是取输出的最大值对应的类别作为预测输出(比如若输出是顺序排列的,则取输出最大值的下标做预测输出),则输出 $\operatorname*{argmax}_i o_i$。但为了使输出层的输出具有直观意义(例如表示概率值),先对网络输出用softmax运算符做归一化,将网络输出值变换成值为正且和为1的概率分布:
$$ \hat{y}_1, \hat{y}_2, \hat{y}_3 = \text{softmax}(o_1, o_2, o_3), $$
其中
$$ \hat{y}_1 = \frac{ \exp(o_1)}{\sum_{i=1}^3 \exp(o_i)},\quad \hat{y}_2 = \frac{ \exp(o_2)}{\sum_{i=1}^3 \exp(o_i)},\quad \hat{y}_3 = \frac{ \exp(o_3)}{\sum_{i=1}^3 \exp(o_i)}. $$
用矢量表示,定义:
$$ \boldsymbol{W} = \begin{bmatrix} w_{11} & w_{12} & w_{13} \\ w_{21} & w_{22} & w_{23} \\ w_{31} & w_{32} & w_{33} \\ w_{41} & w_{42} & w_{43} \end{bmatrix},\quad \boldsymbol{b} = \begin{bmatrix} b_1 & b_2 & b_3 \end{bmatrix}, $$ 样本i的特征为: $$ \boldsymbol{x}^{(i)} = \begin{bmatrix}x_1^{(i)} & x_2^{(i)} & x_3^{(i)} & x_4^{(i)}\end{bmatrix}, $$ 输出层的输出为: $$ \boldsymbol{o}^{(i)} = \begin{bmatrix}o_1^{(i)} & o_2^{(i)} & o_3^{(i)}\end{bmatrix}, $$ 最终的预测概率为: $$ \boldsymbol{\hat{y}}^{(i)} = \begin{bmatrix}\hat{y}_1^{(i)} & \hat{y}_2^{(i)} & \hat{y}_3^{(i)}\end{bmatrix}. $$
则softmax回归对样本$i$分类的矢量计算表达式为
$$ \begin{aligned} \boldsymbol{o}^{(i)} &= \boldsymbol{x}^{(i)} \boldsymbol{W} + \boldsymbol{b},\\ \boldsymbol{\hat{y}}^{(i)} &= \text{softmax}(\boldsymbol{o}^{(i)}). \end{aligned} $$
以上是单样本的矢量表示,若对小批量的矢量表示如下:
给定一个小批量样本,其批量大小为$n$,输入个数(特征数)$d$,输出个数(类别数)为$q$。设批量特征为$\boldsymbol{X} \in \mathbb{R}^{n \times d}$。假设softmax回归的权重和偏差参数分别为$\boldsymbol{W} \in \mathbb{R}^{d \times q}$和$\boldsymbol{b} \in \mathbb{R}^{1 \times q}$。softmax回归的矢量计算表达式为
$$ \begin{aligned} \boldsymbol{O} &= \boldsymbol{X} \boldsymbol{W} + \boldsymbol{b},\\ \boldsymbol{\hat{Y}} &= \text{softmax}(\boldsymbol{O}), \end{aligned} $$
网络结构
softmax网络模型和线性回归一样,依然是单层全连接层网络,可具体看下面的代码。
交叉熵损失函数
有了网络的输出$\boldsymbol{\hat{y}}^{(i)}$(是一组概率值)和真实标签$\boldsymbol{y}^{(i)}$,利用交叉熵损失函数计算损失值$l$。
$$ H(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)} ) = -\sum_{j=1}^q y_j^{(i)} \log \hat y_j^{(i)}, $$
对于一个样本只有一个标签的情况,由于每个样本的标签中只有一个值为1,其他为0,上式可简化为
$$ H(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}) = -\log \hat y_{y^{(i)}}^{(i)} $$
假设训练数据集的样本数为$n$,交叉熵损失函数定义为 $$ \ell(\boldsymbol{\Theta}) = \frac{1}{n} \sum_{i=1}^n H\left(\boldsymbol y^{(i)}, \boldsymbol {\hat y}^{(i)}\right ), $$
优化算法
和线性回归一样,依然是小批量随机梯度下降,具体看下面的代码。
代码实现
|
|