记录应对过拟合的两种策略:权重衰减 (weight decay) 和丢弃法(dropout),并在实验“softmax回归分类”中探究这两种策略和它们的组合在应对过拟合方面的有效性。摘自《动手学深度学习》
过拟合现象,即模型的训练误差远小于它在测试集上的误差。虽然增大训练数据集可能会减轻过拟合,但是获取额外的训练数据往往代价高昂。权重衰减和丢弃法可以有效应对过拟合的现象。
权重衰减等价于𝐿2范数正则化,正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。我们先描述𝐿2范数正则化,再解释它为何又称权重衰减。
𝐿2范数正则化在模型原损失函数基础上添加𝐿2范数惩罚项,从而得到训练所需要最小化的函数。𝐿2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。 以一个线性回归的损失函数为例子:
$$
\ell(w_1, w_2, b) = \frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right)^2
$$
将权重参数用向量$\boldsymbol{w} = [w_1, w_2]$表示,带有$L_2$范数惩罚项的新损失函数为:
$$
\ell(w_1, w_2, b) + \frac{\lambda}{2n} |\boldsymbol{w}|^2,
$$
其中超参数$\lambda > 0$。当权重参数均为0时,惩罚项最小。当𝜆较大时,惩罚项在损失函数中的比重较大,这通常会使学到的权重参数的元素较接近0。当$\lambda$设为0时,惩罚项完全不起作用。上式中$L_2$范数平方$|\boldsymbol{w}|^2$展开后得到$w_1^2 + w_2^2$。有了$L_2$范数惩罚项后,在小批量随机梯度下降中,我们将上面“线性回归”中权重𝑤1和𝑤2的迭代方式更改为:
$$
\begin{aligned}
w_1 &\leftarrow \left(1- \frac{\eta\lambda}{|\mathcal{B}|} \right)w_1 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_1^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right),\\
w_2 &\leftarrow \left(1- \frac{\eta\lambda}{|\mathcal{B}|} \right)w_2 - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}}x_2^{(i)} \left(x_1^{(i)} w_1 + x_2^{(i)} w_2 + b - y^{(i)}\right).
\end{aligned}
$$
可见,$L_2$范数正则化令权重$w_1$和$w_2$先自乘小于1的数,再减去不含惩罚项的梯度。因此,$L_2$范数正则化又叫权重衰减。权重衰减通过惩罚绝对值较大的模型参数为需要学习的模型增加了限制,这可能对过拟合有效。实际场景中,我们有时也在惩罚项中添加偏差元素的平方和。
在损失函数中增加一个惩罚项即可:
1
2
|
def l2_penalty(w):
return (w**2).sum() / 2
|
然后损失函数中:
1
|
l = loss(net(X, w, b), y) + lambd * l2_penalty(w)
|
丢弃法有一些不同的变体。本节中提到的丢弃法特指倒置丢弃法(inverted dropout)。当对网络某一层使用丢弃法时,该层的单元将有一定概率被丢弃掉。以一个单隐藏层的多层感知机为例子,其中输入个数为4,隐藏单元个数为5,且隐藏单元$h_i$(i=1,…,5)的计算表达式为:
$$
h_i = \phi\left(x_1 w_{1i} + x_2 w_{2i} + x_3 w_{3i} + x_4 w_{4i} + b_i\right),
$$
这里$\phi$是激活函数,$x_1, \ldots, x_4$是输入,隐藏单元$i$的权重参数为$w_{1i}, \ldots, w_{4i}$,偏差参数为$b_i$。当对该隐藏层使用丢弃法时,该层的隐藏单元将有一定概率被丢弃掉。设丢弃概率为$p$, 那么有$p$的概率$h_i$会被清零,有$1-p$的概率$h_i$会除以$1-p$做拉伸。丢弃概率是丢弃法的超参数。具体来说,设随机变量$\xi_i$为0和1的概率分别为$p$和$1-p$。使用丢弃法时我们计算新的隐藏单元$h_i'$:
$$
h_i' = \frac{\xi_i}{1-p} h_i.
$$
由于$E(\xi_i) = 1-p$,因此:
$$
E(h_i') = \frac{E(\xi_i)}{1-p}h_i = h_i.
$$
即丢弃法不改变其输入的期望值。由于在训练中隐藏层神经元的丢弃是随机的,输出层的计算无法过度依赖隐藏层中的任一个,从而在训练模型时起到正则化的作用,并可以用来应对过拟合。在测试模型时,我们为了拿到更加确定性的结果,一般不使用丢弃法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
import d2lzh as d2l
from mxnet import autograd, gluon, init, nd
from mxnet.gluon import loss as gloss, nn
def dropout(X, drop_prob):
assert 0 <= drop_prob <= 1
keep_prob = 1 - drop_prob
# 这种情况下把全部元素都丢弃
if keep_prob == 0:
return X.zeros_like()
mask = nd.random.uniform(0, 1, X.shape) < keep_prob
return mask * X / keep_prob
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
W1 = nd.random.normal(scale=0.01, shape=(num_inputs, num_hiddens1))
b1 = nd.zeros(num_hiddens1)
W2 = nd.random.normal(scale=0.01, shape=(num_hiddens1, num_hiddens2))
b2 = nd.zeros(num_hiddens2)
W3 = nd.random.normal(scale=0.01, shape=(num_hiddens2, num_outputs))
b3 = nd.zeros(num_outputs)
params = [W1, b1, W2, b2, W3, b3]
for param in params:
param.attach_grad()
drop_prob1, drop_prob2 = 0.2, 0.5
def net(X):
X = X.reshape((-1, num_inputs))
H1 = (nd.dot(X, W1) + b1).relu()
if autograd.is_training(): # 只在训练模型时使用丢弃法
H1 = dropout(H1, drop_prob1) # 在第一层全连接后添加丢弃层
H2 = (nd.dot(H1, W2) + b2).relu()
if autograd.is_training():
H2 = dropout(H2, drop_prob2) # 在第二层全连接后添加丢弃层
return nd.dot(H2, W3) + b3
num_epochs, lr, batch_size = 5, 0.5, 256
loss = gloss.SoftmaxCrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size,
params, lr)
|
本实验中利用softmax回归分类探究权重衰减和丢弃法应对过拟合的效果。在这里我们增加两个隐藏层。下面定义的模型将全连接层和激活函数ReLU串起来,并对每个激活函数的输出使用丢弃法。我们可以分别设置各个层的丢弃概率。通常的建议是把靠近输入层的丢弃概率设得小一点。损失函数增加$L_2$范数惩罚项。利用Gluon可以直接在构造Trainer实例时通过wd参数来指定权重衰减超参数。默认下,Gluon会对权重和偏差同时衰减。我们可以分别对权重和偏差构造Trainer实例,从而只对权重衰减。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
import d2lzh as d2l
from mxnet import autograd, gluon, init, nd
from mxnet.gluon import loss as gloss, nn
from matplotlib import pyplot as plt
drop_prob1, drop_prob2 = 0.2, 0.5
num_epochs, lr, batch_size = 20, 0.5, 256
lambd = 1e-6
def semilogy(train_loss, train_epoch, test_loss = None, test_epoch = None , title = None,num = None):
plt.figure(num)
plt.title(title)
plt.xlabel('epoch')
plt.ylabel('train_loss')
plt.plot(train_epoch, train_loss)
if test_epoch and test_loss:
plt.plot(test_epoch, test_loss, linestyle=':')
plt.pause(0.1)
def l2_penalty(w):
return (w**2).sum() / 2
def train(net, train_iter, test_iter, loss, num_epochs, batch_size,
trainer_w=None , trainer_b=None):
"""Train and evaluate a model with CPU."""
train_ls, test_ls = [], []
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
with autograd.record():
y_hat = net(X)
l = loss(y_hat, y).sum()
l.backward()
trainer_w.step(batch_size)
trainer_b.step(batch_size)
y = y.astype('float32')
train_l_sum += l.asscalar()
train_acc_sum += (y_hat.argmax(axis=1) == y).sum().asscalar()
n += y.size
train_ls.append(train_l_sum / n)
test_l_sum ,n1 = 0.0 ,0.0
for X1,y1 in test_iter:
y1_hat = net(X1)
l1 = loss(y1_hat,y1).sum()
test_l_sum += l1.asscalar()
n1 += y1.size
test_ls.append(test_l_sum / n1)
test_acc = d2l.evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
semilogy(train_ls,range(1, num_epochs + 1),test_ls,range(1, num_epochs + 1),"loss",1)
plt.waitforbuttonpress()
loss = gloss.SoftmaxCrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
net = nn.Sequential()
net.add(nn.Dense(256, activation="relu"),
nn.Dropout(drop_prob1), # 在第一个全连接层后添加丢弃层
nn.Dense(256, activation="relu"),
nn.Dropout(drop_prob2), # 在第二个全连接层后添加丢弃层
nn.Dense(10))
net.initialize(init.Normal(sigma=0.01))
trainer_w = gluon.Trainer(net.collect_params('.*weight'), 'sgd',
{'learning_rate': lr, 'wd': lambd})
trainer_b = gluon.Trainer(net.collect_params('.*bias'), 'sgd',
{'learning_rate': lr})
train(net, train_iter, test_iter, loss, num_epochs, batch_size, trainer_w , trainer_b)
|
以下是实验改动:
1 . 原始情况如上面的代码,隐藏层使用丢弃法,不使用权重衰减,迭代周期为5.
结果:
1
2
3
4
5
|
epoch 1, loss 1.1250, train acc 0.566, test acc 0.772
epoch 2, loss 0.6197, train acc 0.770, test acc 0.840
epoch 3, loss 0.4963, train acc 0.816, test acc 0.847
epoch 4, loss 0.4487, train acc 0.836, test acc 0.858
epoch 5, loss 0.4156, train acc 0.849, test acc 0.867
|
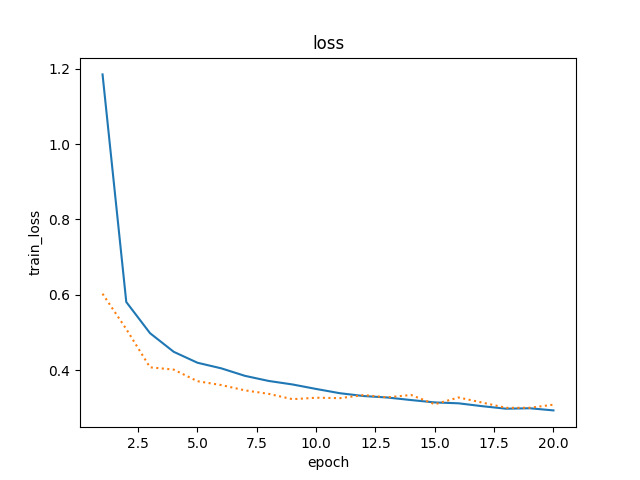
 蓝色折线是train_ls,橙色折线是tesr_ls.
蓝色折线是train_ls,橙色折线是tesr_ls.
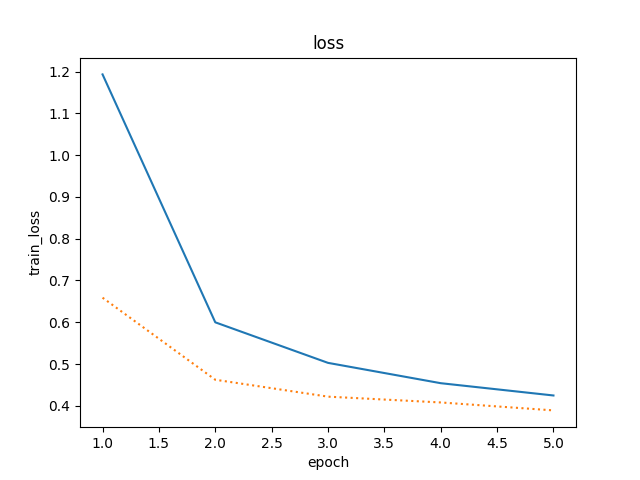
2 . 把本节中的两个丢弃概率超参数对调.
1
2
3
4
5
|
epoch 1, loss 1.1963, train acc 0.532, test acc 0.772
epoch 2, loss 0.6132, train acc 0.772, test acc 0.797
epoch 3, loss 0.5203, train acc 0.808, test acc 0.824
epoch 4, loss 0.4819, train acc 0.824, test acc 0.855
epoch 5, loss 0.4541, train acc 0.832, test acc 0.853
|
 精度稍微下降,通常的建议是把靠近输入层的丢弃概率设得小一点。
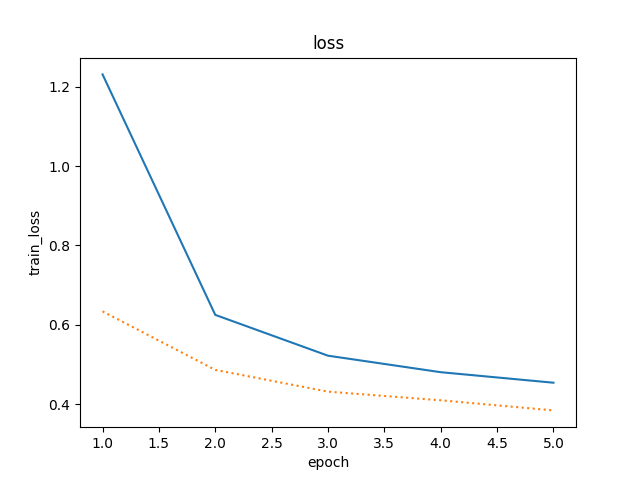
3 . 增大迭代周期数,比较使用丢弃法与不使用丢弃法的结果.
使用丢弃法,迭代周期为20
精度稍微下降,通常的建议是把靠近输入层的丢弃概率设得小一点。
3 . 增大迭代周期数,比较使用丢弃法与不使用丢弃法的结果.
使用丢弃法,迭代周期为20
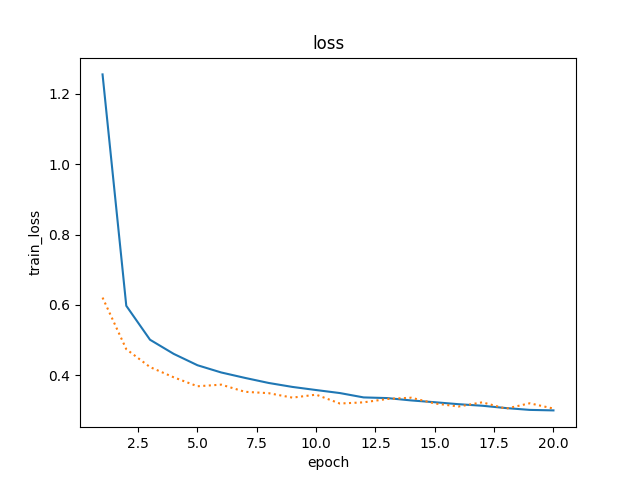
不使用丢弃法,迭代周期为20
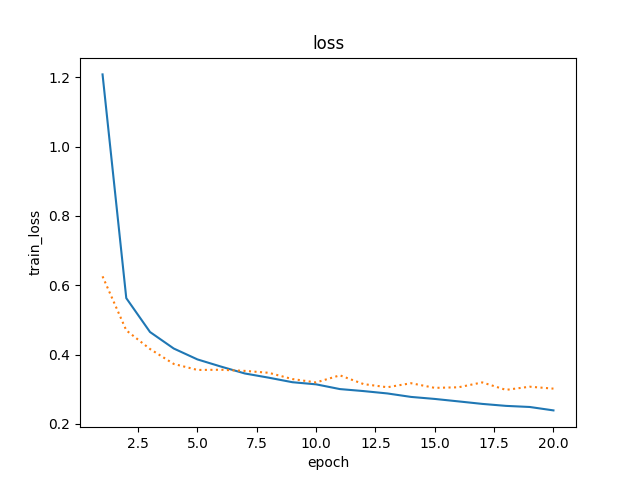
不使用dropout的训练loss更低,但测试loss更高。就是过拟合现象更加明显了。
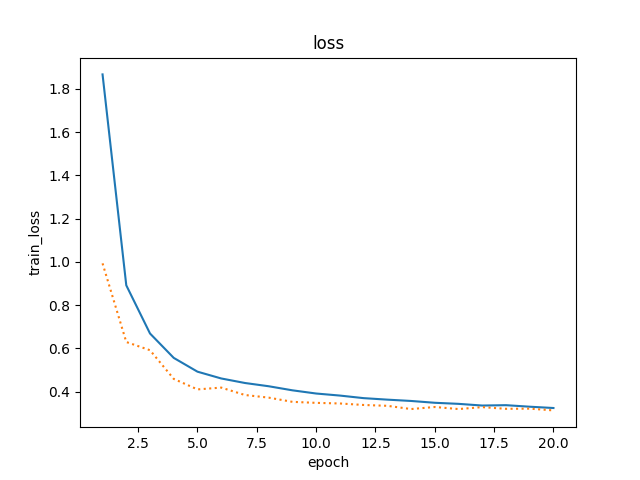
4 . 增加模型复杂度,比如增加一层隐藏层单,迭代周期为了明显期间,设为20,丢弃概率由低层到高层依次为:0.2,0.4,0.6.
增加隐藏层的单元,比如每一层由256改为512,丢弃概率由低到高为:0.2,0.5.
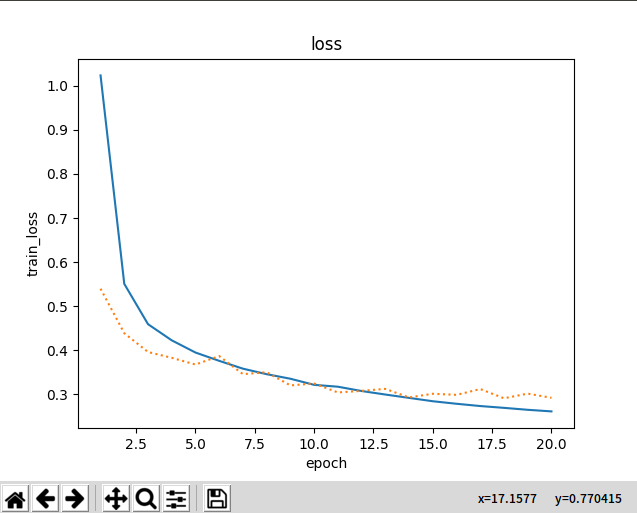
损失有所降低。
5 . 不使用丢弃法,使用权重衰减,epoch为20.
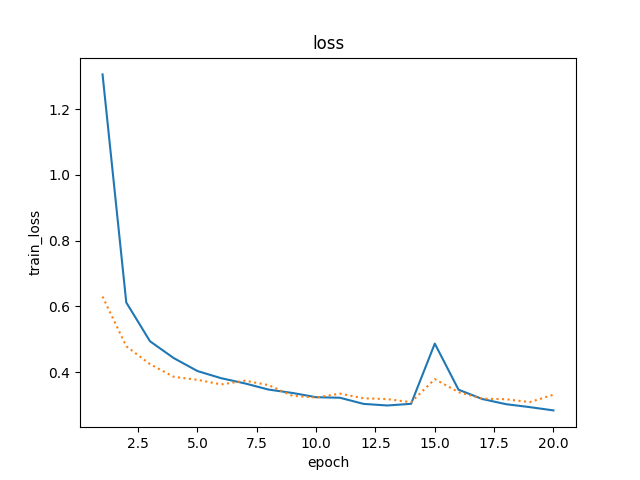
同时使用丢弃法和权重衰减,epoch为20.