记录模型欠拟合和过拟合的原因和实验现象。摘自《动手学深度学习》
网络欠拟合和过拟合
概念
在讨论欠拟合和过拟合之前首先需要区分几个概念:
1 . 训练误差和泛化误差
训练误差(training error)和泛化误差(generalization error)。前者指模型在训练数据集上表现出的误差,后者指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。由于无法从训练误差估计泛化误差,一味地降低训练误差并不意味着泛化误差一定会降低。
2 . 模型选择
在机器学习中,通常需要评估若干候选模型的表现并从中选择模型。这一过程称为模型选择(model selection)。可供选择的候选模型可以是有着不同超参数的同类模型。以多层感知机为例,我们可以选择隐藏层的个数,以及每个隐藏层中隐藏单元个数和激活函数。
3 . 验证数据集
从严格意义上讲,测试集只能在所有超参数和模型参数选定后使用一次。不可以使用测试数据选择模型,如调参。但由于无法从训练误差估计泛化误差,因此也不应只依赖训练数据选择模型。鉴于此,我们可以预留一部分在训练数据集和测试数据集以外的数据来进行模型选择。这部分数据被称为验证数据集,简称验证集(validation set)。然而在实际应用中,由于数据不容易获取,测试数据极少只使用一次就丢弃。一种改善的方法是$K$折交叉验证($K$-fold cross-validation)。在$K$折交叉验证中,我们把原始训练数据集分割成$K$个不重合的子数据集,然后我们做$K$次模型训练和验证。每一次,我们使用一个子数据集验证模型,并使用其他$K−1$个子数据集来训练模型。在这$K$次训练和验证中,每次用来验证模型的子数据集都不同。最后,我们对这$K$次训练误差和验证误差分别求平均。
欠拟合和过拟合是什么
在模型训练中经常出现的两类典型问题:一类是模型无法得到较低的训练误差,我们将这一现象称作欠拟合(underfitting);另一类是模型的训练误差远小于它在测试数据集上的误差,我们称该现象为过拟合(overfitting)。
虽然有很多因素可能导致这两种拟合问题,在主要两个因素是:模型复杂度和训练数据集大小。
- 出现过拟合的情况:模型复杂度太高,训练数据集太小
- 出现欠拟合的情况:模型复杂度太低
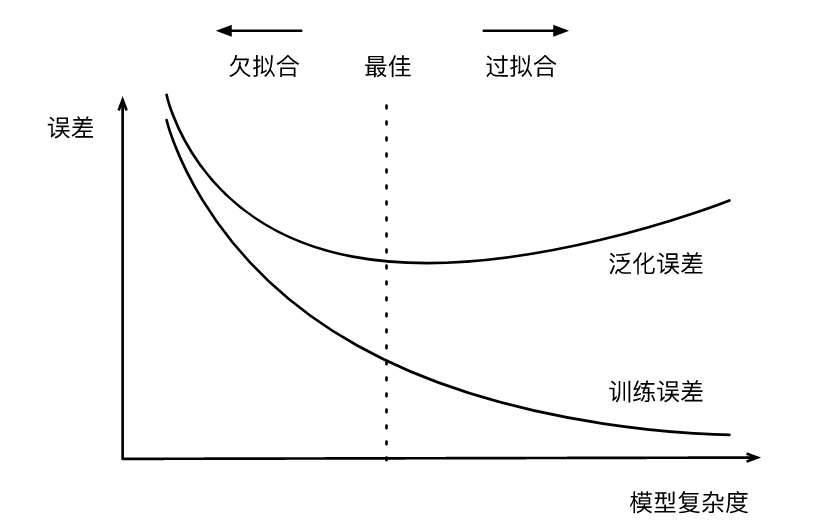 说一个模型的复杂度高低是和训练数据集的数据特征以及数据规模有关的。如果用一个三阶多项式模型来拟合一个线性模型生成的数据,可以说模型复杂度太高了。在实验中发现,此时虽然网络仍然可以较好拟合出线性模型生成的数据的权重(将高阶权重拟合趋向于0),但此时网络对噪声更加敏感了。当训练数据集规模小于网络模型中的参数时候,这使模型显得过于复杂,以至于容易被训练数据中的噪声影响。而且网络倾向于记住数据的每个特征,这时候容易发生过拟合现象(对训练集的特征学的太好了,泛化能力低),此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。相对于欠拟合,我觉得过拟合更容易发生,因为容易设计高复杂度的网络,这时候网络性能瓶颈在于数据规模。
下面代码使用多项式拟合实验来测试模型复杂度和训练数据集大小对欠拟合和过拟合的影响,欠拟合是设计一个线性网络拟合一个多项式网络(模型复杂度太低),过拟合是让输入数据规模减小(训练数据集太小)。
说一个模型的复杂度高低是和训练数据集的数据特征以及数据规模有关的。如果用一个三阶多项式模型来拟合一个线性模型生成的数据,可以说模型复杂度太高了。在实验中发现,此时虽然网络仍然可以较好拟合出线性模型生成的数据的权重(将高阶权重拟合趋向于0),但此时网络对噪声更加敏感了。当训练数据集规模小于网络模型中的参数时候,这使模型显得过于复杂,以至于容易被训练数据中的噪声影响。而且网络倾向于记住数据的每个特征,这时候容易发生过拟合现象(对训练集的特征学的太好了,泛化能力低),此外,泛化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模型。相对于欠拟合,我觉得过拟合更容易发生,因为容易设计高复杂度的网络,这时候网络性能瓶颈在于数据规模。
下面代码使用多项式拟合实验来测试模型复杂度和训练数据集大小对欠拟合和过拟合的影响,欠拟合是设计一个线性网络拟合一个多项式网络(模型复杂度太低),过拟合是让输入数据规模减小(训练数据集太小)。
代码实现
|
|
实验结果:
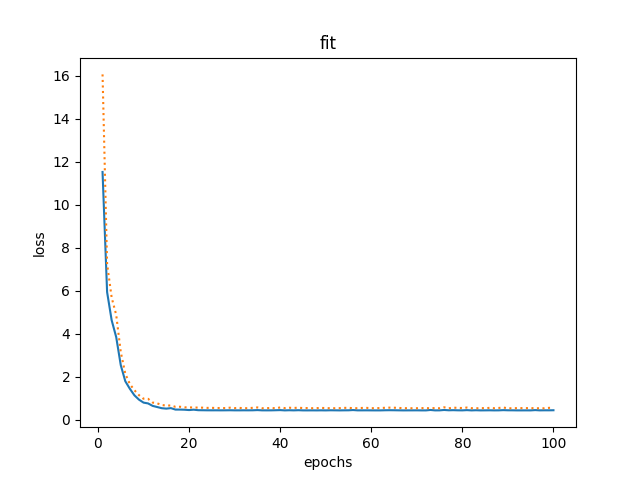
- 拟合
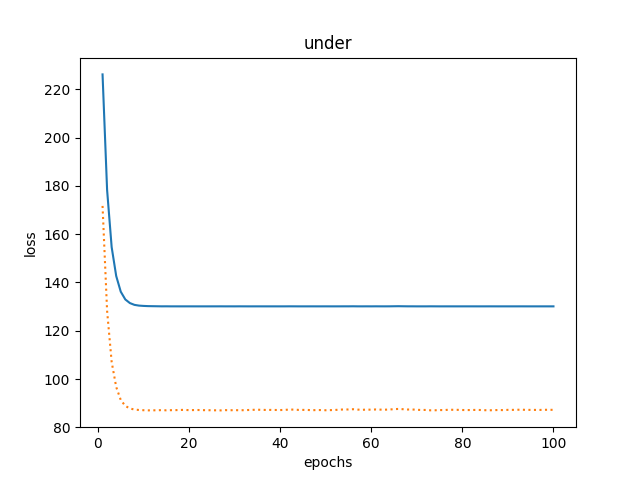
- 欠拟合
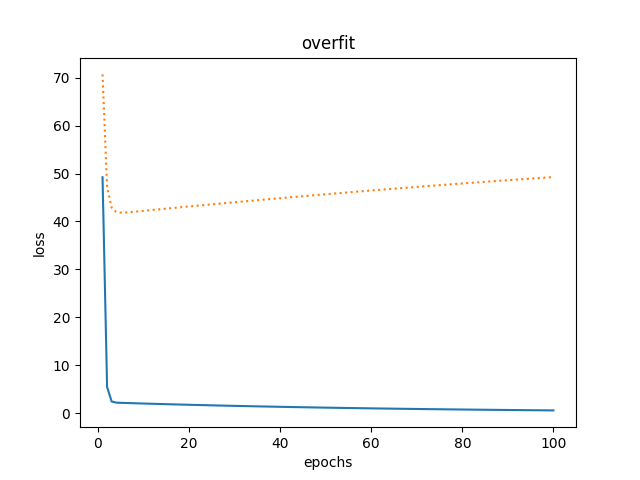
- 过拟合