部分摘自泡泡机器人公开课,原文链接
算法流程
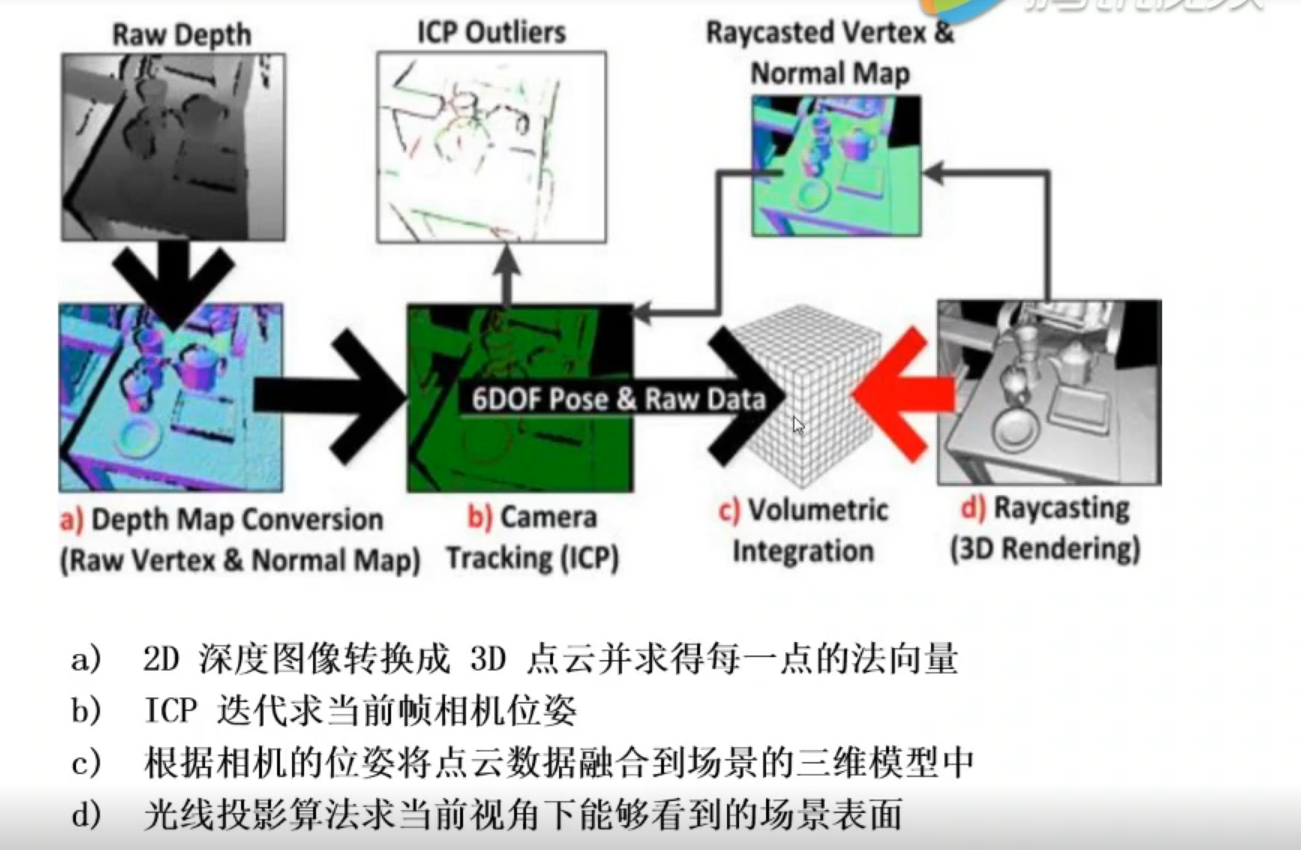
2D 深度图像转换为3D点云并求得每一点的法向量
$$ \mathrm{D}_{k}(\mathbf{u})=\frac{1}{W_{\mathbf{p}}} \sum_{\mathbf{q} \in \mathbb{U}} \mathscr{N}_{\sigma_{s}}\left(||\mathbf{u}-\mathbf{q}||_{2}\right) \mathscr{N}_{\sigma_{r}}\left(\left||\mathbf{R}_{k}(\mathbf{u})-\mathrm{R}_{k}(\mathbf{q})\right||_{2}\right) \mathrm{R}_{k}(\mathbf{q}) $$
$$ \mathbf{V}_{k}(\mathbf{u})=\mathrm{D}_{k}(\mathbf{u}) \mathbf{K}^{-1} \mathbf{\dot { u }} $$
$$ \mathbf{N}_{k}(\mathbf{u})=v\left[\left(\mathbf{V}_{k}(u+1, v)-\mathbf{V}_{k}(u, v)\right) \times\left(\mathbf{V}_{k}(u, v+1)-\mathbf{V}_{k}(u, v)\right)\right] $$
上面第一条公式表示对深度图进行双边滤波操作。第二条公式表示将滤波后的深度图转化为点云。第三条公式为深度图中每个点计算法向量。
ICP算法迭代求当前帧相机位姿
对点云分层抽样并且按照coarse-to-fine的方式匹配。

当然在算法实现的时候,ICP这个操作的计算误差放在GPU上做,一个线程格处理一个像素,每个线程块先单独做误差累积放在显存中,然后这些误差再累加送回CPU内存,最后调整相机位姿。
根据相机位姿将点云数据融合到全局模型中
这里利用到TSDF(截断符号距离函数)模型。TSDF模型中网格的数值代表重建场景表面的距离,所以TSDF模型中数据由正到负过渡,数值为零的点表示重建的表面。
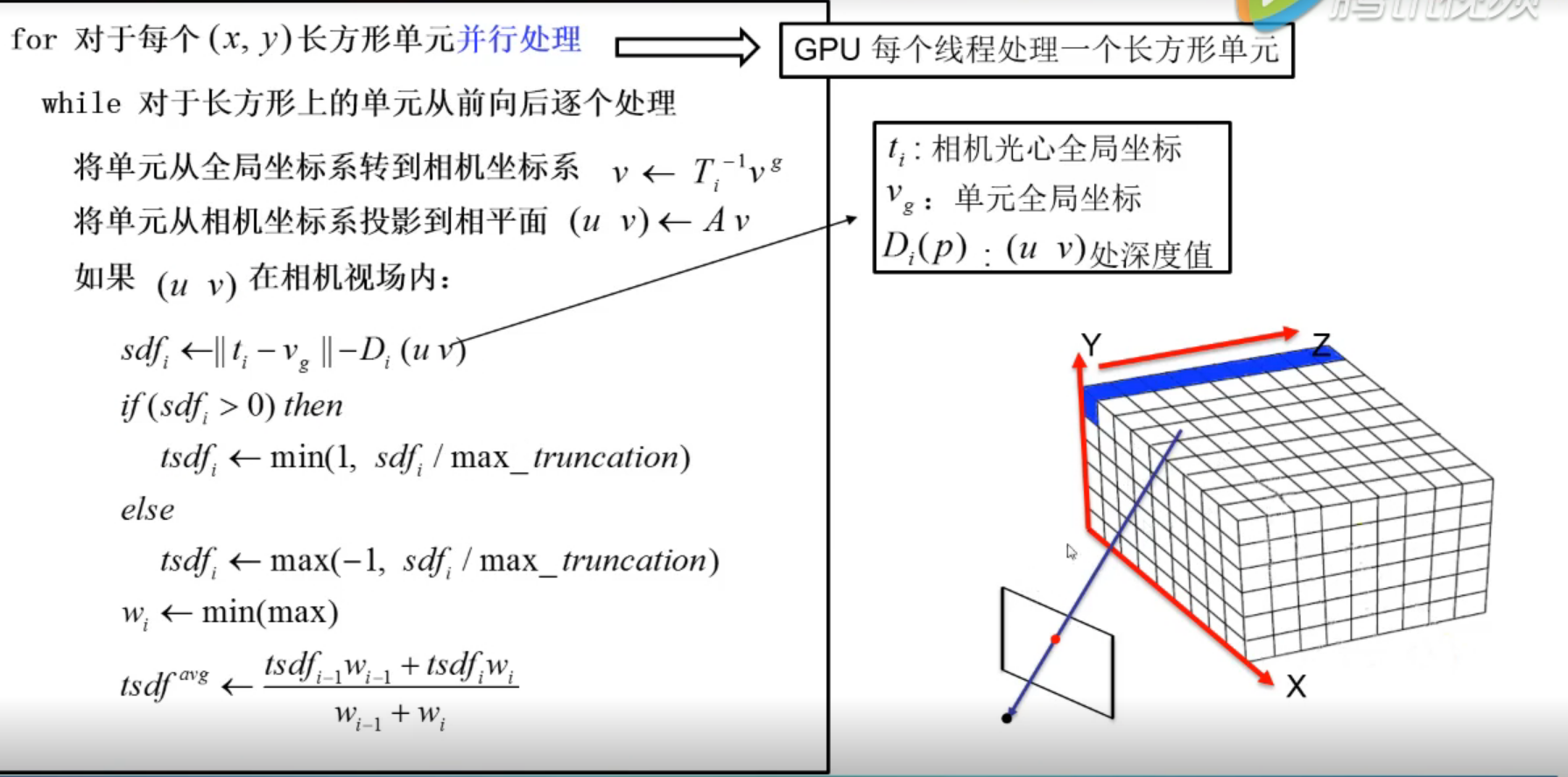
对于每一帧点云,算法需要在GPU中维持TSDF数据,如上图右侧,每一个线程处理一个“蓝条的网格”。首先将,TSDF单元由全局坐标系,由ICP得到的外参数转换到相机坐标系,再由相机内参得到像素坐标系下的值,如果这个像素值在相机视场内,就更新TSDF数据。
更新规则:
如上图左边的更新公式:
相机光心的全局坐标减去TSDF单元的全局坐标表示单元到光心的距离,再减去深度值表征第i个像素的sfd值,如果这个值接近0,说明该值应该更新到模型的表面。下面的截断公式防止离表面过远的单元有太大的更新值。最后将更新的TSDF数据与上一帧的TSDF数据加权融合得到当前TSDF模型。
利用光线投影算法求得当前视角下的场景表面点云
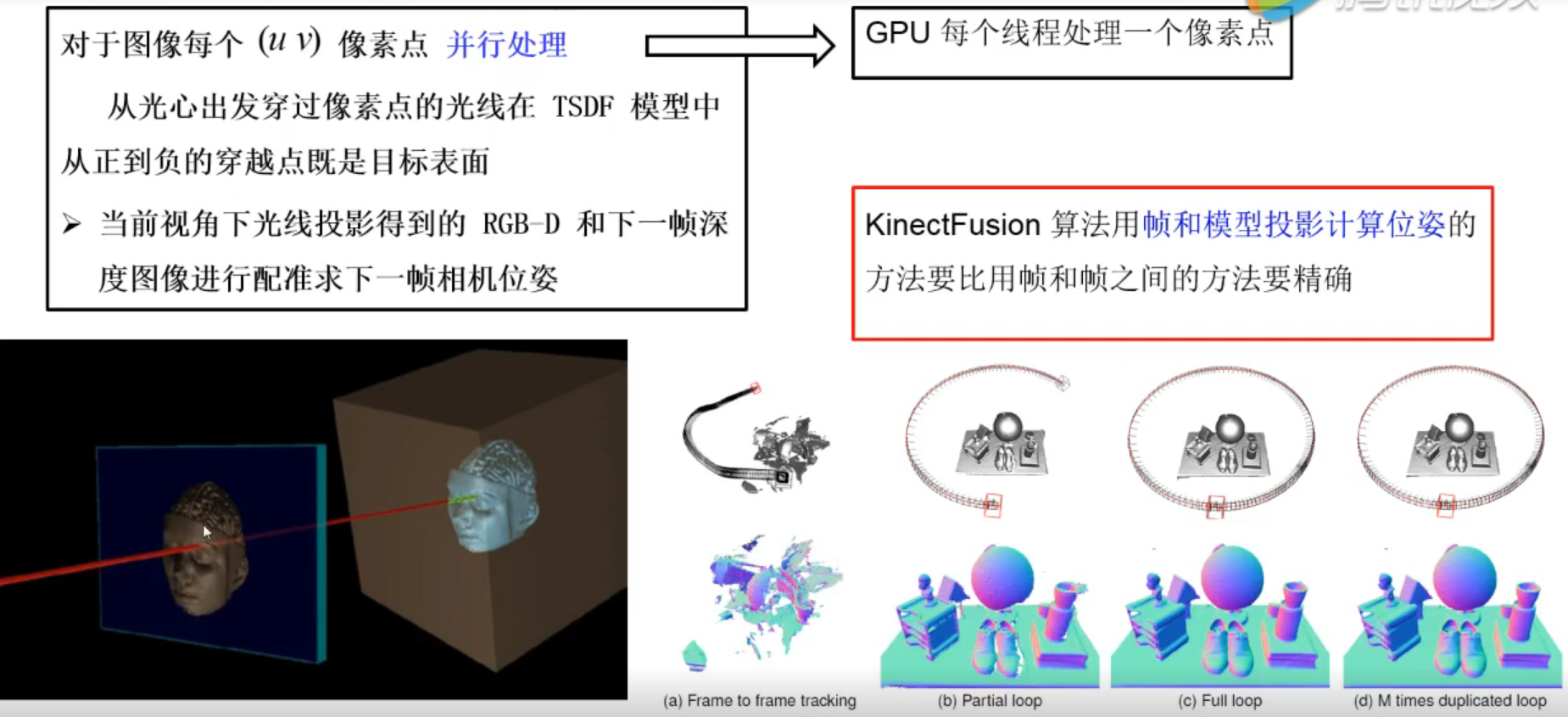
光线投影假设一束从相机光心中投射出来的射线穿过当前的TSDF模型,所有交点的值是由正到负变化的,值为0的位置即为该射线与相机平面的交点对应像素值所对应的点云坐标。这样就可以利用当前TSDF模型做模型投影得到深度图,该深度图用于和下一帧输入的深度图做配准。这样利用帧和模型投影计算的位姿比利用帧和帧之间的方法要准确。
TSDF网格模型的优劣点
优点:
-
网格模型隐含重建好的表面,加权融合消除误差。
-
便于做并行计算
缺点:
-
非常消耗显存,显存使用率和重建场景体积成正比。
-
回环,位姿优化做得差。