1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
|
import csv
import json
image_w = 640
image_h = 640
axis_start_num = 10000
info = {"description": "COCO 2017 Dataset","url": "http://cocodataset.org","version": "1.0","year": 2017,"contributor": "COCO Consortium","date_created": "2017/09/01"}
licenses = [{"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/","id": 1,"name": "Attribution-NonCommercial-ShareAlike License"},
{"url": "http://creativecommons.org/licenses/by-nc/2.0/","id": 2,"name": "Attribution-NonCommercial License"},
{"url": "http://creativecommons.org/licenses/by-nc-nd/2.0/","id": 3,"name": "Attribution-NonCommercial-NoDerivs License"},
{"url": "http://creativecommons.org/licenses/by/2.0/","id": 4,"name": "Attribution License"},
{"url": "http://creativecommons.org/licenses/by-sa/2.0/","id": 5,"name": "Attribution-ShareAlike License"},
{"url": "http://creativecommons.org/licenses/by-nd/2.0/","id": 6,"name": "Attribution-NoDerivs License"},
{"url": "http://flickr.com/commons/usage/","id": 7,"name": "No known copyright restrictions"},
{"url": "http://www.usa.gov/copyright.shtml","id": 8,"name": "United States Government Work"}]
images = []
annotations = []
categories = [{"supercategory": "person","id": 1,"name": "person","keypoints": ["nose","left_eye","right_eye","left_ear","right_ear","left_shoulder","right_shoulder","left_elbow","right_elbow","left_wrist","right_wrist","left_hip","right_hip","left_knee","right_knee","left_ankle","right_ankle"],
"skeleton": []}]
#[16,14],[14,12],[17,15],[15,13],[12,13],[6,12],[7,13],[6,7],[6,8],[7,9],[8,10],[9,11],[2,3],[1,2],[1,3],[2,4],[3,5],[4,6],[5,7]]
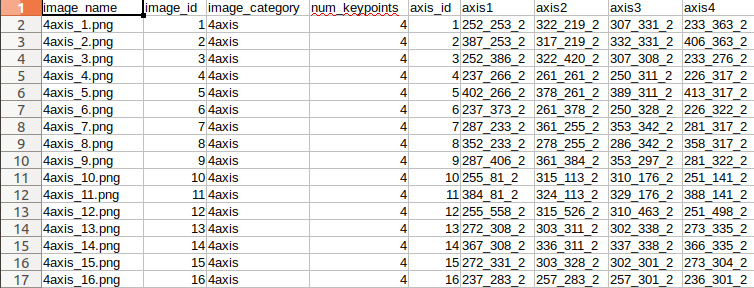
csv_reader=csv.reader(open('/home/jiajie/pytorch/detectron2/datasets/coco/train_vertexs.csv',encoding='utf-8'))
max_image_id = 0
for i,row in enumerate(csv_reader):
if(i!=0):
#images
if(int(row[1])>max_image_id):
image_info = {"license": 1}
image_info['file_name'] = row[0]
image_info['coco_url'] = ""
image_info['height'] = image_h
image_info['width'] = image_w
image_info['date_captured'] = ""
image_info['flickr_url'] = ""
image_info['id'] = int(row[1])
images.append(image_info)
max_image_id = int(row[1])
# annotations
annotations_info = {"segmentation":[[]]}
annotations_info['num_keypoints'] = int(row[3])
annotations_info['area'] = 0.0
annotations_info['iscrowd'] = 0
keypoints_dict = {}
rank_kp_list = []
for n in range(5,9):
keypoints_dict[str(row[n])+"_"+str(n)] = pow(int(str(row[n]).split("_")[0]),2)+pow(int(str(row[n]).split("_")[1]),2)
rank_kp_list.append(keypoints_dict[str(row[n])+"_"+str(n)])
#rank_kp_list.sort()
sort_list = sorted(keypoints_dict.items(), key=lambda d: d[1], reverse=False)
#print(keypoints_dict)
#print(sort_list)
keypoints_list = []
keypoints_list.append(int(str(sort_list[0][0]).split("_")[0]))
keypoints_list.append(int(str(sort_list[0][0]).split("_")[1]))
keypoints_list.append(int(str(sort_list[0][0]).split("_")[2]))
keypoints_list.append(int(str(sort_list[1][0]).split("_")[0]))
keypoints_list.append(int(str(sort_list[1][0]).split("_")[1]))
keypoints_list.append(int(str(sort_list[1][0]).split("_")[2]))
keypoints_list.append(int(str(sort_list[2][0]).split("_")[0]))
keypoints_list.append(int(str(sort_list[2][0]).split("_")[1]))
keypoints_list.append(int(str(sort_list[2][0]).split("_")[2]))
keypoints_list.append(int(str(sort_list[3][0]).split("_")[0]))
keypoints_list.append(int(str(sort_list[3][0]).split("_")[1]))
keypoints_list.append(int(str(sort_list[3][0]).split("_")[2]))
annotations_info['keypoints'] = keypoints_list
annotations_info['image_id'] = int(row[1])
# bbox
x_list = []
y_list = []
for n in range(5,9):
if(int(str(row[n]).split("_")[2])!=0 ):
x_list.append(int(str(row[n]).split("_")[0]))
y_list.append(int(str(row[n]).split("_")[1]))
min_x = min(x_list)
min_y = min(y_list)
max_x = max(x_list)
max_y = max(y_list)
annotations_info['bbox'] = [min(max(0,min_x-(max_x-min_x)/4),int(image_w)),min(max(0,min_y-(max_y-min_y)/4),int(image_h)),3*(max_x-min_x)/2,3*(max_y-min_y)/2]
if(int(row[1])==588):
print(min_x,min_y,max_x,max_y)
print(annotations_info['bbox'])
annotations_info['category_id'] = 1
annotations_info['id'] = axis_start_num+int(i)
annotations.append(annotations_info)
image = {
'info': info,
'licenses': licenses,
'images': images,
'annotations': annotations,
'categories': categories
}
with open('/home/jiajie/pytorch/detectron2/datasets/coco/annotations/person_keypoints_train2017.json', 'w') as f:
json.dump(image,f)
|